 |
|
- KH Coderについて質問をしたいときには
- KH Coderを最短でマスターできる近道は?
- KH Coderのインストールやエラーについて
- 「安全にダウンロードすることはできません」「一般的にダウンロードされていません」「お使いのデバイスに問題を起こす可能性があるため、ブロックされました」などと表示されてダウンロードできません(Edge)
- 「ダウンロードしたユーザー数が少ないため、デバイスに問題を引き起こす可能性があります」と表示されてダウンロードできません(Internet Explorer 11)
- 「WindowsによってPCが保護されました」と表示されてインストールできません(Windows)
- KH Coderが正常に起動しません(Windows)
- 「新規プロジェクト」画面が「応答なし」になります
- 「新規プロジェクト」画面で「ファイルを開けない」旨のエラーが出ます
- 「前処理の実行」中にエラーが出ます
- 「ファイル処理に失敗しました」というエラーが出ます
- KH Coderが「応答なし」と表示されます(Windows)
- KH Coder上の文字やプロットがぼやけて見えます(Windows)
- MacでKH Coderを使うにはどうすればよいですか?
- いくつかのメニュー項目が灰色で表示されていて、選択できません
- MacのParallels上でWindowsを動かしており、そのWindows上でKH Coderを使おうとしていますが、うまく動作しないようです。対策はありますか?
- 抽出語について
- 入力データとその準備について
- KH Coderを使って分析するためには、どのようにデータを準備すればよいですか?
- 1つのプロジェクトにつき、分析対象ファイルを1つしか登録できないようですが、KH Coderは複数の文書を扱えないのですか?
- KH Coderではどの程度の大きさのファイルまで分析できますか?
- 大きなファイルの処理にはどの程度の時間がかかりますか?
- 英語テキストを分析できますか?
- 中国語・韓国語・ロシア語テキストを分析できますか?
- 古文テキストを分析できますか?
- 分析対象ファイルを修正・変更した場合は、新たなプロジェクトとして登録しなければならないのですか?
- 「H5」の数が、分析対象Excelファイルの行数より少なくなるのはなぜですか?
- 「H5」の数が、分析対象Excelファイルの行数よりも多くなるのはなぜですか?
- 外部変数について
- コーディングについて
- 分析結果について
- 普通は1つのクロス表に対して1つのカイ2乗値ですが、なぜKH Coderの「クロス集計」には複数のカイ2乗値が載っているのですか?
- なぜKH Coderの「クロス集計」では、パーセントの値を横に合計しても縦に合計しても100%にならないのですか?
- 対応分析の結果の読み取り方を教えてください
- 対応分析の「成分」とは何ですか?
- 対応分析の結果、すべての語が1直線上に乗っていて、横軸も縦軸も「成分1」と表示されますが、これは何かの間違いですか?
- 対応分析の結果を示したところ「馬蹄形ではないか」と指摘されました。「馬蹄形」の結果には何か問題があるのでしょうか?
- 対応分析の結果(語の座標)を取り出して、他のソフトでプロットを作り直すには?
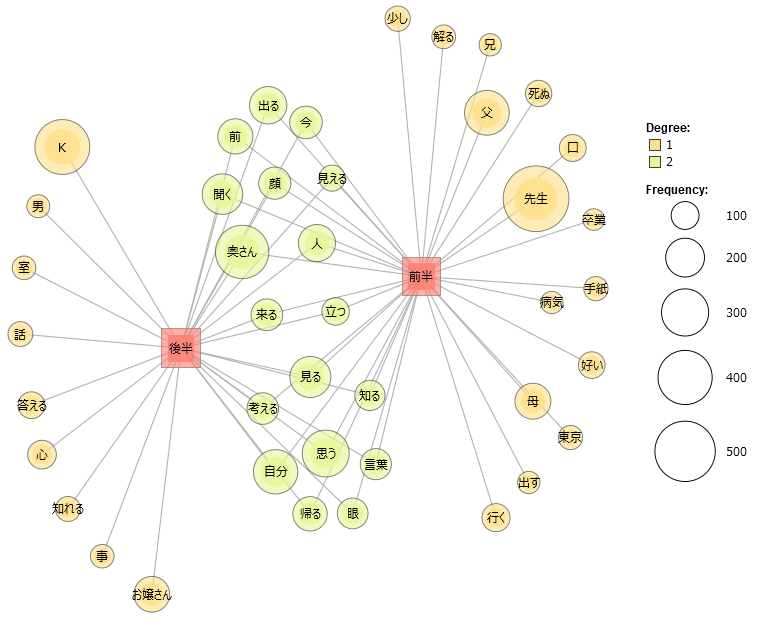
- 共起ネットワークの実線と点線の違いを教えてください
- 共起ネットワークではどのように共起関係の強さを図っているのですか? Jaccard係数とは何ですか?
- 共起ネットワークに描かれている共起関係の強さを数値で確認するには?
- 共起ネットワークに出てこない語があります
- 共起ネットワークの語の位置を編集するには?
- KH CoderのプロットをIllustratorで編集するには?(Windows環境)
- WordMinerとKH Coderとの連携・併用について
- カスタマイズや自動化について
- その他
KH Coderについて質問をしたいときには
◆Windows版の不具合やバグの報告
Windows版の不具合やバグと思われる現象については、(株)SCREEN アドバンストシステムソリューションズ様にお問い合わせいただくか、下記ユーザーフォーラム(掲示板)をご利用下さい。
◆それ以外のお問い合わせ・ご質問
次の2つの窓口をご利用いただけます。
[1] (株)SCREEN アドバンストシステムソリューションズ様ご提供の「KH Coderオフィシャルパッケージ」(Pro Edition以上)を購入することで、 同社のQ & A対応窓口をご利用いただけます。これなら確実に助けを得られますし、非公開で質問をすることができます。
[2]ユーザーフォーラム(掲示板)に質問を投稿することもできます。ただし、ご質問と回答を蓄積してほかの方にも役立つようにという観点から、公開の場でのやり取りとなります。また掲示板はユーザー同士で助け合う場ですので、必ず助けを得られるとは限らないことをあらかじめご了承ください。投稿にはGitHubへの登録が必要です(無料)。新たな投稿を行うには、GitHubにSign inした上でユーザーフォーラム(掲示板)を開き、緑色の「New Discussion」ボタンをクリックしてください。Sign inしないとこのボタンは表示されないようです。
これら2つ以外の窓口では、個別のご質問をお受けしていません。恐れ入りますが、開発者のメール・SNS等ではご質問を承っていません。
なお、質問をしなくても、本ページの「よくある質問」群に加えて、以下の資料をご利用いただくと問題が解決する場合がございます。また、学生さんでしたら、授業やゼミでご指導いただいている先生に教えを請うのも一手ではないでしょうか。
- ユーザーフォーラム(掲示板)や旧掲示板に投稿されたこれまでのQ & A
- チュートリアル
- 公式入門書
- 詳細マニュアル +alpha
KH Coderを最短でマスターできる近道は?
次のような順番で資料を利用されることをお勧めします。
- 操作方法: 公式入門書
- 論文・レポートの執筆例: 『リスク社会を生きる若者たち』の第9章
- 執筆&査読チェックポイント: 中村・周・樋口(2025)
- さらに深く: KH Coderの本
KH Coder開発陣による解説を聞いてから以上の資料にあたった方が、読みやすくなることは間違いないでしょう。
なお1.の公式入門書は、「手順」コーナーの操作をぜひご自身でも行ないながらお読みください。4.のKH Coderの本は、通読というより、必要なときに必要な箇所をめくっていただくのが良いかもしれません。
| KH Coderのインストールやエラーについて |
KH Coderには、分析対象データを外部に送信(アップロード)する機能がありますか?
分析データが外部へ送信されることは一切ありません。KH CoderではローカルPCの内部ですべての分析処理・可視化が完結します。この点がWebページ上で分析を行うサービスとの大きな違いです。
「安全にダウンロードすることはできません」「一般的にダウンロードされていません」「お使いのデバイスに問題を起こす可能性があるため、ブロックされました」などと表示されてダウンロードできません(Edge)。
こちらのページに記載の手順をお試しください。
「ダウンロードしたユーザー数が少ないため、デバイスに問題を引き起こす可能性があります」と表示されてダウンロードできません(Internet Explorer 11)。
こちらのページに記載の手順をお試しください。
「WindowsによってPCが保護されました」と表示されてインストールできません(Windows)。
こちらのページに記載の手順をお試しください。
KH Coderが正常に起動しません(Windows)
■ウイルス対策ソフト
たとえばNorton 360のようなウイルス対策ソフトが動作していると、KH Coderが起動しない場合があります。ウイルス対策ソフトを一時的に無効にしてお試しいただくのが一手です。
その際、KH Coderをダウンロードとインストールを行う時点から、ウイルス対策ソフトを無効にしておかないと起動しなかったというご報告も複数いただいております。いったん既存のKH Coderをアンインストールし、ダウンロードしたファイルを削除して、ウイルス対策ソフトを無効にした上で、ダウンロードからやり直してみてください。
なお「电脑管家」というソフトウェアがインストールされている場合も、これを終了しないとKH Coderが起動しなかったり、勝手にボタン類がクリックされたかのような動きをするというご報告を複数いただいています。
■インストール場所
デフォルトの「C:\KHCoderOfficialPackage」以外のフォルダにKH Coderをインストールしている場合、インストール先を変更せずに、デフォルトの解凍先でお試し下さい。
■それでも起動しなければコンソールの表示内容を調べて掲示板へ
それでもKH Coderが起動しない場合には、コンソール画面の表示内容とともに、掲示板に書き込んでいただけると助かります。コンソール画面とは、KH Coder起動時に最初に出てくる黒背景に白文字の画面です。コンソール画面は、タスクバーに最小化される場合もありますが、KH Coderが起動に失敗する場合は、単に消えてしまって、内容を確認できない場合が多いです。
コンソール画面が消えてしまう場合は、次の手順で、コンソール表示の内容をご確認の上、掲示板にご投稿ください。
- スタートボタン(画面一番下、やや左の方にあるWindowsの旗のボタン)をクリックして、「すべてのアプリ」→「Windowsツール」から「コマンドプロンプト」ダブルクリック。
- 以下の2行を、1行ずつコマンドプロンプトに貼り付けて「Enter」キーを押していくことでKH Coderを起動。
- cd C:\KHCoderOfficialPackage
- .\kh_coder
この手順ならば、コマンドプロンプト(コンソール)画面が消えずに残るので、表示を最後までご確認いただけるかと存じます。表示内容を書き写すのは大変と思います。コピー&ペーストしていただくかスクリーンショットを貼り付けていただくのが手軽です。
※KH Coderオフィシャルパッケージでは、この手順でもコンソール画面が消えてしまって、内容を確認できないかもしれません。その場合は(株)SCREEN アドバンストシステムソリューションズ様にお問い合わせ下さい。
「新規プロジェクト」画面が「応答なし」になります
KH Coderの解凍先(Unzip先)はデフォルトの「C:\khcoder3」でしょうか。
日本語・中国語・韓国語などの文字(半角英数以外の文字)を含むフォルダにKH Coderを置くと、うまく動作しない場合があります。またデスクトップなど、同期(OneDrive・Dropbox・Google Drive等)されているフォルダ内に解凍すると、うまく動かないことがあります。これらのソフトは、データの同期時中にファイルの内容が変更されないよう「保護」するため、同じファイルをKH Coderが処理しようとするとエラーになります。
デフォルトの「C:\khcoder3」に解凍してお試しいただくか、同期を一時停止してからお試しください。
「新規プロジェクト」画面で「ファイルを開けない」旨のエラーが出ます
分析対象ファイルの名前や、それを格納しているフォルダの名前に、日本語・中国語・ハングルなどの文字が含まれると、まれにこのエラーになります。英数字のみの命名にしてお試しください。たとえば、分析対象ファイルの名前を「data01.xlsx」として、kh_coder.exeと同じ場所に置いて、プロジェクトを作成してみてください。
(Windowsの画面表示は日本語だけど、中国語のファイル名にしている場合など、Windowsの言語とファイル名の言語が違う場合にこのエラーになりやすいです)
「前処理の実行」中にエラーが出ます
[1] まずはチュートリアル・データなら正常に処理できるかどうかをご確認下さい。
- 新規プロジェクト作成時に,チュートリアルとして付属の「c:\khcoder3\tutorial_jp\kokoro.xls」ファイルを選択。
- 「前処理」->「前処理の実行」
これで問題なく処理を行えるようであれば,KH Coderは正常に動作しています。
[2] チュートリアル・データなら正常に処理できるのにご自身のファイルでエラーが出る場合には、ファイル内容に原因がありそうです。この場合は、「前処理」を行う前に、「テキストのチェック」→「自動修正」の「実行」をクリックで問題が解決する場合が多いです。
[3] チュートリアル・データでも同様のエラーになるなら、KH Coderが正常に動作していません。KH Coderをデスクトップ等にインストールしている場合はデフォルトの「C:\khcoder3\」フォルダに解凍し直してお試し下さい。
[4] またKH CoderをインストールしたフォルダをOneDrive・Dropbox・Google Drive等で同期しないでください。これらのソフトは、データの同期時中にファイルの内容が変更されないよう「保護」するため、同じファイルをKH Coderが処理しようとするとエラーになります。同期を一時停止してから試したり、同期されていないフォルダにKH Coderを解凍して下さい。
[5] ウイルス対策ソフトがKH Coderの処理を妨害することがありますので、ウイルス対策ソフトを一時的に無効にしてお試しいただくのが一手です。
[6] 「MySQLデータベースの処理に失敗」というエラーが表示され、エラー画面の最下部に「The table 'rowdata' is full」と表示されている場合は、次の手順でKH Coderの設定を変更してください。
メニューから「プロジェクト」→「設定」をクリックして、開いた画面で「前処理効率化のためにデータをRAMに読み出す」のチェックを外して、「OK」をクリックします。
「ファイル処理に失敗しました」というエラー・メッセージが出ます
OneDrive・Dropbox・Google Drive等でKH Coder関連のデータを同期している場合に、このエラーが発生することがあるようです。これらのソフトはデータの同期時中に、ファイルの内容が変更されないよう「保護」するため、同じファイルをKH Coderが処理しようとするとエラーになります。KH Coderを動かす際には、Dropboxの同期を一時停止すると良いでしょう。
これらの点を確認しても同じエラー・メッセージが出てしまう場合は、上記[1]~[5]の手順をおためし下さい。
KH Coderが「応答なし」と表示されます(Windows)
KH Coderは処理に「専念」するため、OS(Windows)から見て「応答なし」と判断されることもありますが、それで正常です。 タスクマネージャーを見て、KH CoderがCPU(コア1つ分)やディスクを使っていれば、正常に処理を実行しています。
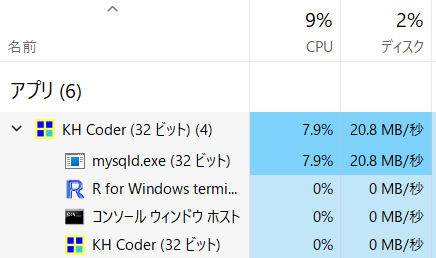
CPUもディスクも使っていなくて「応答なし」だと、本当に何かエラーが起こっているのかもしれません。その状態が長く続くようなら、強制終了が必要かもしれません。再現性があるようなら、ご自身の操作内容やコンソール画面の表示内容とともに掲示板へご報告ください。
KH Coder上の文字やプロットがぼやけて見えます(Windows)。
デスクトップPCの4Kモニタや、ノートPCの高解像度モニタの場合、KH Coderの画面表示をWindowsが(無理矢理)拡大するために、KH Coder上の文字やプロットがぼやけてしまうことがあります。この場合には以下の対策が有効です。
■Windowsによる拡大をオフにする
- 「kh_coder.exe」または「kh_coder」のアイコン上で右クリックして「プロパティ」を選択
- プロパティ画面の「互換性」タブで「高DPI設定の変更」をクリック
- 開いた画面で「高いDPIスケールの動作を上書きします」にチェックして「OK」をクリック
- プロパティ画面に戻るのでここでも「OK」をクリック
以上でWindowsによる拡大(ぼやけてしまう低品質な拡大)が無効になります。もしKH Coderのプロットや文字が小さく見える場合、以下の手順でKH Coder側での拡大を行ってください。
■KH Coderのプロットを拡大
- KH Coderを起動してメニューから「プロジェクト」「設定」を選択
- 設定画面で「デフォルトのプロットサイズ」を、長辺1280、短辺960として、「OK」をクリック ※お使いのモニターにあわせて960x600、1600x1200など、任意の数値をご指定いただけます。
■KH Coderの文字表示を拡大する(必要に応じて)
- KH Coderを起動してメニューから「プロジェクト」「設定」を選択
- 設定画面で「フォント設定」の「変更」をクリックし、より大きな「サイズ」を選択してから「OK」
- 設定画面に戻るのでここでも「OK」をクリック
- KH Coderを再起動
MacでKH Coderを使うにはどうすれば良いですか?
有償サポートの一環としてご提供中のMac版自動設定ソフトウェアをご利用いただけます。手順を見ながらその通りにインストール操作を行っていただく必要があるなど、Widows版とは若干の違いがありますが、廉価にてご提供しています。
いくつかのメニュー項目が灰色で表示されていて、選択できません
メニューの「ツール」「抽出語」の先の項目、例えば「抽出語リスト」「KWICコンコーダンス」などの項目が灰色で表示されていて選択できない場合があります。前処理を行なっていない場合はこの状態になりますので、メニューの「前処理」から「前処理の実行」を選択してください。
この他、Rがインストールされていなかったり、KH CoderがRを認識できていない場合、「対応分析」「共起ネットワーク」などのRを利用する項目が灰色で選択できなくなります。
MacのParallels上でWindowsを動かしており、そのWindows上でKH Coderを使おうとしていますが、うまく動作しないようです。対策はありますか?
デフォルトの「C:\KHCoderOfficialPackage」にKH Coderをインストールして使用してください。データも「C:\KHCoderOfficialPackage」内に置いていただくと安全です。
Parallelsで、MacとWindowsでデスクトップを共有する設定にしていると、デスクトップのパス(コンピュータ内での住所みたいなもの)が特別な設定になります。このためKH Coderをデスクトップに置くと動作に支障がでることがわかりました。デスクトップだけでなく、ドキュメント・フォルダも同様と考えられます。
| 抽出語について |
出現回数ではなく、いくつの文書に各抽出語が含まれているかを集計するには?
時として、抽出語が何回データ中に出現していたかという「出現回数(TF)」ではなく、いくつの文書中に出現していたかという文書数(DF)/出現件数を集計したいこともあるでしょう。こうした集計を行えば、例えば自由記述データの場合、何人の回答者がその語に言及していたのかを調べることができます。
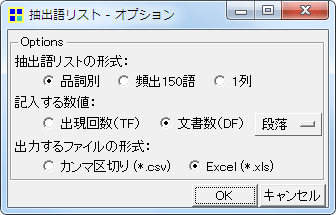
メニューから「ツール」「抽出語」「抽出語リスト」→「Excel出力」,または「プロジェクト」「エクスポート」「抽出語リスト(Excel向け)」をクリックして、上図のオプション画面で「文書数(DF)」を選択すれば、こうした集計を行えます。
※以前は以下のようなSQL文を実行する必要がありましたが、現在では上のようなマウス操作でOKです。
KH Coderのメニューから「ツール」「SQL文の実行」をクリックして、以下のSQLを実行すると、文書数/出現件数の多いものから順に150語をリストアップすることができます。結果として表示されるDFの列が文書数/出現件数を表し、TFが出現回数を表しています。またこのSQL文では、「抽出語リスト(品詞別・出現回数順)」をもとに作成する「頻出150語の表」の場合と同じ品詞を選択し、リストアップを行います。
なお上のSQLでは、それぞれの段落を「文書」と見なしています。すなわち、それぞれの文書ないしは回答が、改行で区切られているデータを想定しいます。これを段落ではなく文に変更するには、上のSLQで「df_dan」となっているところを、「df_bun」に変更して下さい。また、H1見出しで括った部分を1つの「文書」と見なしたい場合は「df_h1」のようにします。
次に、「語A、語B、語Cの文書数/出現件数を知りたい」というような場合には、以下のようなコーディングルールをお使いいただけます。
*コードA 語A *コードB 語B *コードC 語C
「コーディング」→「単純集計」画面で「頻度」と表示される数値が、文書数/出現件数にあたります。
助詞や助動詞などの機能語を検索・集計するには?
デフォルトの品詞設定では、KH Coderは助詞や助動詞などの機能語には「その他」という品詞名を与えます。そして、「その他」という品詞名を与えられた語は基本的に無視され、「抽出語リスト」にも載りませんし、検索や集計の対象にもなりません。
こうしたKH Coderの品詞設定を変更するには、「kh_coder.exe」と同じ場所の「config」フォルダを開き、その中にある「hinshi_chasen」というファイルをテキストエディタで開きます。Windowsのメモ帳ではなく、サクラエディタ(フリー)や秀丸エディタ(シェア)のような、文字コードがEUCのファイルを扱えるテキストエディタをお使い下さい。
例えば、助詞と助動詞を分析対象としたい場合は、以下の2行をこのファイルの末尾に加えます。
30,助詞,助詞
31,助動詞,助動詞
以上の操作によってKH Coderの品詞設定が変更されるので、助詞や助動詞に「その他」ではなく「助詞」「助動詞」といった品詞名が与えられるとともに、検索・集計の対象となります。※ただし、既存のプロジェクトについては、前処理を再度実行するまでは変更が反映されません。以上の操作に加えて、前処理を再度実行して下さい。
次に、より詳細な品詞設定の例を考えてみましょう。茶筌は助詞を「助詞-格助詞」「助詞-係助詞」などに分類していますが、もしこのうち「助詞-格助詞」だけを取り出したいという場合は、以下の1行を「hinshi_chasen」ファイルに追加します。
30,格助詞,助詞-格助詞
さらに、茶筌は格助詞についても「助詞-格助詞-一般」「助詞-格助詞-連語」などの区別を行っています。このうち「助詞-格助詞-一般」だけを取り出して、「格助詞」としてKH Coder上で扱うには、以下の1行を「hinshi_chasen」ファイルに追加します。
30,格助詞,助詞-格助詞-一般
これらの記述の紫色の部分は、KH Coder上での品詞名を表します。ここには自由な品詞名を指定することが出来ます。赤色の部分はKH Coder上での品詞番号です。他の品詞の番号と重複しないように注意して下さい。そして緑色の部分が、茶筌の出力する品詞名です。こうした記述によって、「茶筌の出力した品詞名がAであれば、KH Coder上ではBという品詞名を与える」という指定を行えます。なお緑色の部分については前方一致で処理が行われているので、「助詞」とだけ指定すると、「助詞-格助詞」など、「助詞」で始まるものがすべてヒットします。
なお、KH Coderの品詞体系の詳細についてはマニュアルの2.2節を、茶筌の出力する品詞名については茶筌のマニュアルの末尾をご覧下さい。茶筌のマニュアルは、「kh_coder.exe」がある場所から見て、「dep\chasen\doc\manual-j.pdf」に同梱されています(Windows版パッケージの場合のみ)。
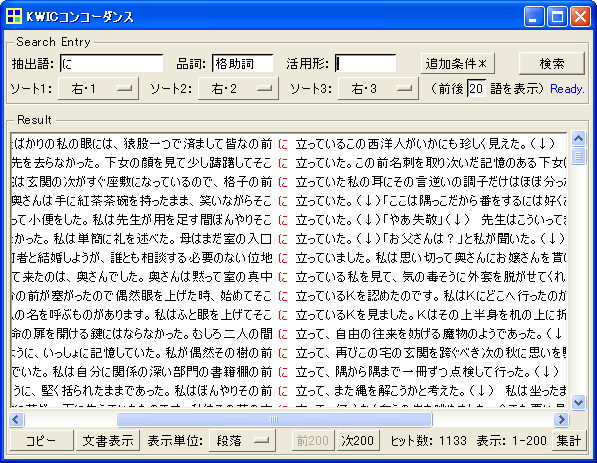
上図はこうした設定を行って、漱石「こころ」から、格助詞「に」の直後に動詞があるケースを検索した結果です。ヒット数から、こうしたケースは1,133件あったことが分かります。
ご自身でUniDicをインストール・設定していただくことで可能です。KH Coderに同梱のMeCabや茶筌の設定を変更しても良いですし、別途MeCabとUniDicをインストールして使用してもよいでしょう。KH Coderの設定画面で、どのパスにインストールされたMeCab・茶筌を使用するのか選択できます。
大きく分けて、
- コーディング
- 有料プラグイン
- 対策プラグイン(スクリプト編集)
という3つの方策が考えられます。
■コーディング
KH Coder開発においては,分析を2つの段階に分けて行うことを考えています。そして分析の段階1,すなわち抽出語の分析の段階では,「旅館」と「ホテル」を統一するような操作を行わないことをお勧めしています。データ全体にわたってこうした統一を行おうとすると思いのほか消耗しますし,分析者の先入観や予断をデータに押しつけてしまうこともあるからです。
その上で分析の段階2,すなわちコーディングルールを作成する段階で,「旅館」「ホテル」「宿」などの語を,「*宿」というコンセプトとして数えるよう指定するのがお勧めです。ここでは,段階1の分析結果を見ながら,分析者が注目したいコンセプトだけに絞って取り出せば良いので,労力の面でも有利です。またコーディングルールで明示的に指定し、分析結果とともに公開するなら,「*宿」というコンセプトをあらわす語として,「旅館」「ホテル」をはじめ,好きな語を指定して問題ありません。
次のようなコーディングルール・ファイルを作成して、[ツール]→[コーディング]メニュー内の分析機能をお使いください。下記の語A・語Bのような形で語を並べていけば数十語を分析に用いることも可能です。
*宿
旅館 or ホテル or 宿*語A
語A*語B
語B
なおこの考え方においては,機械が自動的に取り出す「語」と(段階1)、人間が意図的に取り出す「コンセプト(コード)」とを(段階2),混同するのは良くないことです。このため,語とコードを交ぜての分析は原則として行えません。この考え方について詳しくは,書籍をご参照いただけましたら幸いです。
■有料プラグイン
もっとも分析の1つ目の段階,すなわち抽出語を使った分析の段階でも,「かわいい」と「カワイイ」をまとめるといった統合を行いたいというご要望は継続的にいただいておりました。そうした統合を行えた方が便利な時も,確かにあるかもしれません。(株)SCREENアドバンストシステムソリューションズ様より発売中の有料プラグイン「文錦® 表記ゆれ&同義語エディター for KH Coder」をお使いになれば,そうした統合の操作を簡単に行っていただけます。なお、本プラグインはWindows版のみのご提供です。
■対策プラグイン(スクリプト編集)
手作業によるスクリプト編集が必用になりますが、有料プラグインを購入しなくとも、対策プラグインによる語の統合も可能です。ただし正確かつ確実にスクリプト編集等の操作を行わないと、エラーが出てKH Coderが起動しなくなりますし、エラーが出なくても正しくない集計結果となる恐れがあります。エラーが出てどうして良いかわからなかったり、不安を感じられる場合は、上記の有料プラグインをお勧めいたします。
■強制抽出
こうした場合は、KH Coderのメニューから「前処理」「語の取捨選択」と進んで、「強制抽出する語」の欄に「人間関係」を追加してください。こうした手当てをしない場合、KH Coder(茶筌/MeCab)は一番小さい単位まで語を分割する傾向があります。
■複合語(専門用語)を自動的に見つけ出せないの?
「人間関係」のように、手当てをしないと分割されてしまうような語を「複合語」と呼びます。KH Coderのメニューから「前処理」「複合語の検出」「茶筌を利用」を選択すると、データ中の複合語を洗い出すことができます。出てきたリストの中から、必要なものを上記の「強制抽出」欄に追加しましょう。
ただし、複合語が分割されても、共起ネットワーク上で「人間」と「関係」がつながっていれば、「あぁ、人間関係ね」と解釈することは十分可能です。あまりこの部分に神経質になる必要はないでしょう。
■茶筌・MeCabの辞書を編集するという方法も
KH Coderは日本語データ中から語を取り出すために、茶筌またはMeCabを用いています。よって、これらの辞書を編集することで複合語や専門用語に対応することも可能です。
医療用語を取り出したいのですが、「強制抽出」機能で頑張るしかないのでしょうか?
「万病辞書データ」と「百薬辞書データ」に加えて、「ComeJisyo」を使わせていただいて、KH Coder(MeCab)で使える医療用語辞書を作りました。よろしかったらご利用ください。下記URLからダウンロードできます。「使用法」もよくご覧下さい:
https://github.com/ko-ichi-h/khcoder/discussions/1258#discussioncomment-9637284
韓国語の抽出語に数字が付いているものがありますが、この数字は何ですか?
KH Coderは韓国語テキストから語を取り出すためにHanDicを使用しています。HanDicは抽出語に同音異義語がある場合、「標準国語大辞典」の同音異義語番号を付してくれます。
| 入力データとその準備について |
KH Coderを使って分析するためには、どのようにデータを準備すればよいですか?
「メモ帳」「サクラエディタ」「秀丸」のようなテキストエディタにデータを入力するか、あるいは「Excel」や「Calc」のような表計算ソフトにデータを入力します。どんな分析をしたいかによって、適したデータ準備の形式は変わりますので、以下、場合別にご紹介します。
■全体に多く出現する言葉やテーマを知りたい場合【テキストファイル作成】
テキストエディタに、文章を入力するだけでOKです。「抽出語リスト」「共起ネットワーク」などのコマンドをご利用ください。
「共起ネットワーク」のかわりに、「多次元尺度構成法(MDS)」「クラスター分析」「自己組織化マップ」を使ってもよいでしょう。
■2つ~3つ程度の文書をお互いに比べてみたい場合【別個のテキストファイル】
2つ~3つのテキストファイルにそれぞれの文書を入力して保存するのが簡単でしょう。それぞれを別々のプロジェクトとしてKH Coderに登録し、別々の抽出語リスト・共起ネットワークを作成します。そして、頻出150語の表を2~3並べて比べてみたり、同様に共起ネットワークを並べて見比べるとよいでしょう。
なお、1枚の図表に情報を要約したり、統計的な比較を行ないたい場合には、1つ下に記載の見出しで区切る方法が有効です。
■3~10以上の文書の特徴を見たい場合【テキストファイルを見出しで区切る】
たとえば「<H1>○○○</H1>」というような行を、H1タグをつけた見出しと言います。このような見出し行を入れることで、1つのテキストファイルをいくつかの部分に区切ることができます。なお、別々のファイルに保存した文書を、見出しで括った1つのテキストファイルに自動的にまとめることもできます。
| <H1>文書1の見出し</H1> 文書の内容・・・ <H1>文書2の見出し</H1> 文書の内容・・・ <H1>文書3の見出し</H1> 文書の内容・・・ |
こうしたファイルを作成すれば、対応分析や見出しを使った共起ネットワーク、特徴語一覧によって、それぞれの文書を比較することができます。
{kind=link}
コーディングルールを作成すれば、それぞれの文書に多く出現するコンセプトをヒートマップやバブルプロットで調べることもできます。
■いろいろな要因による文書の変化を見たい場合【CSV・Excelファイルの作成】
アンケートの自由記述を分析するときには、性別・年代・学歴などなど、いろいろな変数によるテキストの変化を見たいでしょう。こうした場合は、表計算ファイルにデータを入力する方法が良いでしょう。
使う変数を選ぶだけで、性別ごと、年代ごと、学歴ごとの特徴を調べることができます。方法としては、1つ上の項目に出てきた方法(対応分析や見出しを使った共起ネットワークなど)すべてを利用できます。
1つのプロジェクトにつき、分析対象ファイルを1つしか登録できないようですが、KH Coderは複数の文書を扱えないのですか?
いえいえ、複数の文書を扱うことができます。ただし、すべての文書を1つのファイルにまとめて入力し、そのファイルをKH Coderに登録していただく必要があります。
例えば3つの文書を比較して、それぞれの文書の特徴を知りたいといった場合には、漱石「こころ」のチュートリアルで「上」「中」「下」の特徴を調べたのとまったく同じ手順で、分析を行っていただけます。すなわち、「<h1>ここから文書1<h2>」といった見出しを3つ入力することで、1つのファイル内で、文書を3つに区切って分析することができます。
このような見出しを加えつつ、複数のファイルの内容を1つのファイルに結合する処理を、KH Coderのプラグインによって自動的に行うことができます。具体的な手順についてはこちらのページの「始める前の準備」と「第5章の練習問題」をご覧ください。
KH Coderではどの程度の大きさのファイルまで分析できますか?
分析対象ファイルのサイズについては、200MB程度までは実際に試したことがありますし、理論上は特に制限はありません。 強いて書くならば、設計上、データサイズの上限はMySQLの性能に依存します。しかし、これまでに見聞きした範囲では、MySQLの上限に行き当たるよりも先に、ディスクスペースが埋まってしまう場合の方が多いようです。
ただし、こうした大きなファイルを分析する際には、処理に非常に長い時間がかかることと、分析対象ファイルの100倍程度の空き容量がHDDに必要なことにご注意下さい。さらに前処理を実行する前に、メニューから「プロジェクト」「設定」をクリックし、「前処理効率化のためにデータをRAMに読み出す」のチェックを外しておくと安全です。
また、Rは大規模データに必ずしも対応していない面があるため、大規模データを扱う場合はRを使った多変量解析が上手く行かない場合があります。具体的には、エラーが出て結果が表示されない場合や、実行に何時間もかかる場合があります。
データサイズが大きすぎるためにRを用いた多変量解析が上手く行かない場合には、以下のような方策が考えられます。
- データサイズを縮小したくない場合には、Rではなく、大規模データに対応した統計ソフトをご利用いただくとと良いでしょう。「文書x抽出語」表の出力コマンドを使ってKH Coderからデータを取り出し、大規模データを扱える統計ソフトで解析していただく形になります。
- KH CoderのRを用いた多変量解析機能を利用されたい場合には、ランダム・サンプリングを行うことでデータサイズを縮小されるのが一手でしょう。日本人は1億2千万人以上いますが、きちんとランダム・サンプリングを行いますと、2500人も集めれば±2%程度の誤差で日本人の様子を調べることができます。KH CoderからRに分析用データとして送られるのは「文書x抽出語」表ですが、ここでの文書数を100,000以下、抽出語数を100以下に抑えれば比較的短時間で解析結果を得られるでしょう。現在のKH Coderは,「文書×抽出語」表をRに送る際に,ランダムサンプリングを行うことでデータを縮小する機能を備えています。
データが大きいと,Rによる可視化(共起ネットワーク等)がエラーになる場合がありました。Rは全データをメモリ上に読み出すためです。この問題を回避するため,Rに送るデータをランダムサンプリングによって縮小する機能を加えました。#次期バージョンの新機能 pic.twitter.com/0R63S6f8b5
— KH Coder (@khcoder) 2019年3月3日 - 上記2つの中間的な方法として、Rに送る「文書x抽出語」表のサイズが小さくなるように工夫することが考えられます。目安は上に挙げたとおり、文書数100,000以下、抽出語数100以下です。
- 抽出語数については、品詞や出現数などを使って100以下におさえると良いでしょう。
- 文書数については、文単位ではなく、段落単位/文章単位での分析を考えると良いでしょう。「同じ段落/文章に登場する語は?」といった文脈情報を解析に利用できる上に、文の数よりも段落/文章の数の方が圧倒的に少ないので、「文書x抽出語」表のサイズも小さくなります。
仮にデータが新聞記事であれば、文単位で解析せずに記事単位で解析すると良いでしょう。あるいはTwitterのようなデータであれば、1つ1つのtweetを「文書」と見なすのではなく、一連の対話をまとめて1つの「文書」と見なすような前処理を行うとよいかもしれません。
- 抽出語の共起ネットワーク作成やクラスター分析・多次元尺度法などを行う場合には、さらに別の方策もあります。「抽出語x文脈ベクトル」表の出力コマンドを使ってデータを取り出せば、文書数が何十万あっても、任意のサイズの行列にデータを圧縮することができます。行数は分析に使う単語数と等しくなりますが、列数は任意に設定できるので、5,000~10,000程度にすれば良いでしょう。
このコマンドで(圧縮して)取り出したデータをRに読み込めば、共起ネットワーク作成やクラスター分析・多次元尺度法などを行うことが出来ます。ご自身でRを操作していただく必要があるのですが、別途KH Coderでこれらの分析を実行し、その結果をRコマンド形式で保存したファイルを参考にしていただけば、比較的やりやすいかと思います。
※文書数100,000・抽出語数100を一応の目安として示していますが、このうち抽出語数100については、画面上にプロットすることを考慮した値です。すなわち、100を超える数の語をプロットしても、確認が難しいだろうという判断です。プロットを行わないような場合には、もう少し増やしても良いでしょう。例えば文書のクラスター分析では、文書数5,000・抽出語数3,000程度で分析を行うことも考えられます。
上記2と3を組み合わせることで「文書x抽出語」表のサイズを抑えるか、あるいは4の方法をとるかというのが個人的にはお勧めでしょうか。なお、ここでサイズを抑える必要があるのは、あくまで「文書x抽出語」表のようなRに送るデータ行列のサイズであり、分析対象ファイルの容量(MB)はさほど問題になりません。
大きなファイルの処理にはどの程度時間がかかりますか?
199MBの新聞記事データ(約110,000件)と、ランダムサンプリングによって15MB(約8,000件)まで縮小したデータの処理を行ってみました。処理に要した時間を下表にまとめています。参考までに、文書数は同等に多いものの、容量(MB)が小さいデータの処理時間も示しています。
|
データ種別
|
文書数 |
容量
|
前処理
|
共起ネットワーク
|
|
新聞記事(大)
|
110,000
|
199MB
|
06:24:16
|
00:15:46
|
|
新聞記事(小)
|
8000
|
15MB
|
00:07:04
|
00:01:03
|
|
論文タイトル
|
106,000
|
5MB
|
00:02:41
|
00:01:38
|
計測PC: Core2Quad Q9650@4Ghz、4GB RAM、SSD(Intel X-25M)
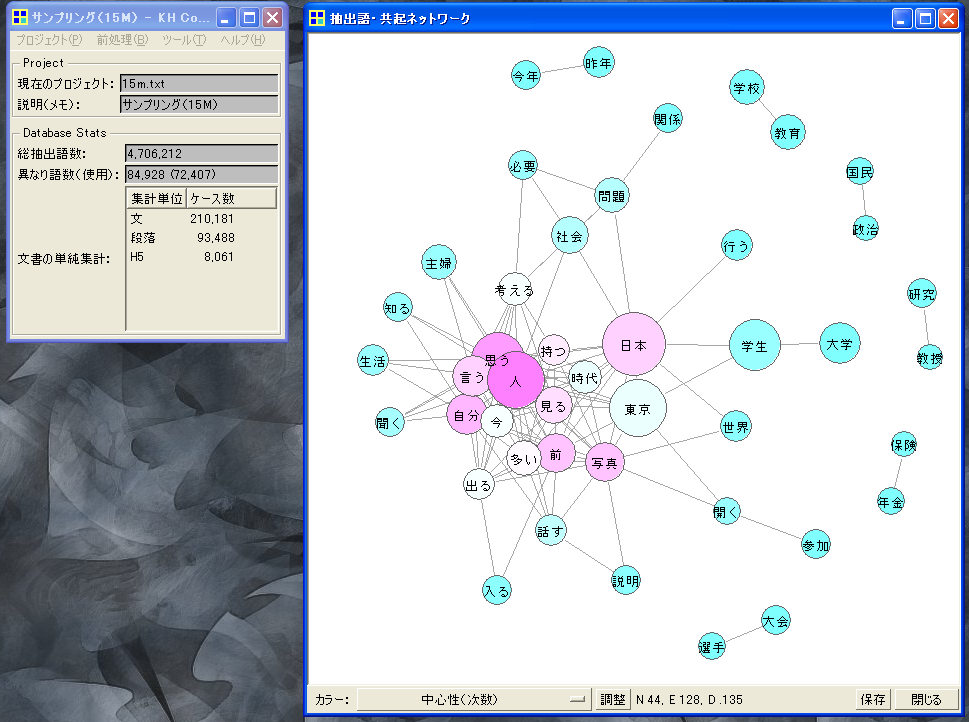
所要時間の表示は「時間:分:秒」です。サンプリングによって縮小したファイルと、もとの大きなファイルでは処理時間に大きな違いがあります。データ分析の際には、様々な分析を行って結果を比較したいことがよくありますから、この処理時間の差は非常に大きいと言えるでしょう。
 |
 |
|
|
全データ(199MB)
|
サンプリング後(15MB)
|
ここで、もとの199Mのデータと、ランダム・サンプリングによって15Mまで減らしたデータとを比べると、分析結果である共起ネットワークが非常に似通っていることがわかります。配置こそ変化していますが、語と語とのつながりはおおむね同じです。例えば「日本」「東京」「学生」「大学」のあたりを比べてみてください。
1つ上の項目でも書きましたが、日本人は1億2千万人以上います。ですが、きちんとランダム・サンプリングを行いますと、2500人も集めれば±2%程度の誤差で日本人の様子を調べることができます。いかに大規模データが手元にあるとしても、サンプリングを活用されることがお勧めです。サンプリングによって縮小したデータでまずは分析を行い、もしも「このトピックに関するデータがもっと欲しい」ということになれば、元データからの検索・サンプリングをやり直すとよいでしょう。KH Coderを使用する限り、100MB単位までならなんとかなりますが、ときおり噂を聞くような100GB単位の巨大コーパスについては、そのまま分析するのは現実的ではありません。
英語テキストを分析できますか?
はい、英語のほかにも、フランス語・ドイツ語・イタリア語・ポルトガル語・スペイン語・カタロニア語などの西ヨーロッパ言語に対応しています。
英語データ分析のための手順については、英語版チュートリアルをご覧ください。
中国語・韓国語・ロシア語テキストを分析できますか?
Ver. 3からは中国語・韓国語・ロシア語・カタロニア語データの分析にも対応しました。中国語の分析にはStanford POS Taggerを、韓国語の分析にはHandicを、ロシア語・カタロニア語の分析にはFree Lingを使用しています。
またVer. 3では、フランス語・イタリア語・ポルトガル語・スペイン語データから、より正確に語の基本形を取り出せるようになりました。Ver. 2では単純な規則で語尾を切り落とすStemmingのみの対応でしたが、辞書にもとづくlemmatizationが可能になりました。lemmatizationにはFree Lingを使用しています。
古文テキストを分析できますか?
MeCabおよび古文用UniDicSを使わせていただくことで分析が可能です。古文用UniDicSには「近代口語小説UniDic」「旧仮名口語UniDic」「中古和文UniDic」をはじめ、さまざまなバリエーションがあるので、データに適したものをお選び下さい。下図は源氏物語・夕顔の共起ネットワークです。※古いバージョンの中古和文UniDicを使用しました。

こうした分析のためには、MeCabや辞書の設定を行い、さらにKH Coderの品詞設定などを変更する必要があります。以下にWindows上での設定例を示します。
- MeCabの実行ファイルを64bit版に入れ替える
- 「kh_coder.exe」がある場所から「dep」「mecab」とフォルダをたどり、
- その中の「bin」フォルダを「bin32」のようにリネーム(改名)する
- MeCab64_bin.zip内の「bin」フォルダを同じ場所にコピーする
※このMeCab 64bit版はこちらのリポジトリで公開されているインストーラーに含まれていたものです。
- 中古和文UniDicをダウンロードし、任意の場所に解凍する
- mecabrcを編集して、中古和文UnidicをMeCabの標準(デフォルト)辞書とする
- 「kh_coder.exe」がある場所から「dep」「mecab」「etc」とたどり、「mecabrc」を秀丸・サクラエディタなどのテキストエディタで開く
- 「dicdir = $(rcpath)\..\dic\ipadic」という箇所の「=」の後を、UniDicをインストールした場所へと変更
- 上書き保存
- 中古和文Unidicに、ChaSenと同じ形式で出力する設定を追加する
- UniDicをインストールしたフォルダの「dicrc」を秀丸・サクラエディタなどのテキストエディタで開く
- 末尾に以下の3行を追加:
node-format-chasen = %m\t%f[6]\t%f[7]\t%F-[0,1,2,3]\t%f[4]\t%f[5]\n
unk-format-chasen = %m\t%m\t%m\tUNKNOWN\t\t\n
eos-format-chasen = EOS\n - 上書き保存
- KH Coderの品詞設定を中古和文Unidicにあわせて変更する
- 「C:\khcoder3\config」フォルダの「hinshi_mecab」を秀丸・サクラエディタなどのテキストエディタで開く
- 内容(全体)を以下のようなものに変更して上書き保存
以上で設定は完了です。あとは、プロジェクト作成時にデフォルトの茶筌ではなくMeCabを選択すればMeCabと中古和文Unidicを使用できます。なお最後の品詞設定は、辞書(この場合は中古和文Unidic)の品詞体系と分析の目的に応じて適宜調節します。
分析対象ファイルを修正・変更した場合は、新たなプロジェクトとして登録しなければならないのですか?
再度プロジェクトを作成する必要はありません。前処理を再度行うことで、変更内容がKH Coderに取り込まれます。再度前処理を行うには、KH Coderのメニューから「前処理」「実行」を順にクリックして下さい。

上図のような画面が表示され、「元ファイルの内容を再度読み込みますか?」と聞かれます。ここで「はい」を選択すると、変更内容が取り込まれます。
ただし、外部変数を読み込んでいて、なおかつケース数が変わるという場合には、この方法は使えません。例えば、もともと新聞記事が500件あって、外部変数として掲載面・日付などを読み込んでいる状態を考えます。ここに記事を何件か付け足したいというような場合は、新たなプロジェクトとして登録しなければなりません。再度前処理を行っただけでは、外部変数(掲載面・日付)と記事の対応がとれなくなってしまうためです。
「H5」の数が、分析対象Excelファイルの行数より少なくなるのはなぜですか?
Excelファイルを分析する場合、Excelファイルに含まれるデータ行数と「H5」は同じ数になるはずです。たとえば漱石『こころ』チュートリアルの場合、Excelファイルの全体行数は1216で、1行目は見出しなので、データ行数は1215です。KH Coderによる「H5」(セル数)の認識も1215となっています。


ところが、KH Coderによる「H5」(セル数)の認識が、データ行数よりも少ない場合には、データの読み込みが中断してしまって、データを部分的にしか読み込んでいないと考えられます。データの読み込みが止まる原因の多くは、文字化けしている部分があったり、制御文字(画面には表示されない特別な役割を持つ文字)が混入していることです。
こうした場合には、データをクリーニングすることで問題が解決します。日本語データであれば、KH Coderのメニューから「前処理」「テキストのチェック」と進め、開いた画面で「自動修正」の部分にある「実行」ボタンをクリックしてください。それから再度、「前処理」を実行してください。
日本語以外のデータの場合には、ExcelのClean関数を使うことで、制御文字をすべて削除できます。なおClean関数を使うと、セル内の改行もすべてなくなりますので注意してください(改行も一種の制御文字であるためです)。Clean関数でクリーニングを行ってから前処理をやり直すか、新たなプロジェクトを作成してください。
「H5」の数が、分析対象Excelファイルの行数より多くなるのはなぜですか?
Excelファイルを分析する場合、Excelファイルに含まれるデータ行数と「H5」は同じ数になるはずです。たとえば漱石『こころ』チュートリアルの場合、Excelファイルの全体行数は1216で、1行目は見出しなので、データ行数は1215です。KH Coderによる「H5」(セル数)の認識も1215となっています。
ところが、KH Coderによる「H5」(セル数)の認識が、データ行数よりも多い場合には、なにか余計なものを読み込んでいることが考えられます。よくあるのは、Excelファイル内のデータから離れたところに、見えない文字等が混入しているケースです。例えば、下図の選択部分(C1222)に全角スペースが入力されているといったケースです。

こうした場合には、(見出し行を含めて)データ部分だけを選択してコピーし、新しいExcelファイルに貼り付けると解決する場合が多いです。
逆方向のアプローチとして、データが入力されていないはずの部分をすべて選択し、「すべてクリア」して上書き保存することでも解決できるでしょう。CtrlキーとShiftキーを押しながら、さらに「→」や「↓」キーを押すことで、広い範囲をかんたんに選択できます。ただ、こうした操作に慣れていない場合は、データだけを選択して新しいファイルに張り付けるアプローチの方が簡単かもしれません。

| 外部変数について |
外部変数とは何ですか?
KH Coderでは、テキスト型データに含まれていない情報を「外部変数」として読み込み、検索やコーディングのための条件として利用することができます。
例えば新聞記事を分析する場合であれば、新聞記事が掲載された日付や、掲載された面などを、外部変数として読み込むことが考えられます。また、アンケート調査の自由回答項目を分析する場合は、性別・年齢・職業・学歴など(の通常の質問項目)を外部変数として読み込むと良いでしょう。
いったん外部変数を読み込めば、例えば、男性の回答中に特に多くあらわれる言葉のリストを表示したり、「男性の回答中に単語Aが出現していれば」といった条件での検索・コーディングを行うことができます。また、コーディング(数え上げ)の結果を、男女別に集計することもできます。
外部変数を読み込むにはどんなファイルを用意すればよいのですか?
※現在では、下記のように「テキスト」と「外部変数」で別個のファイルを作成するよりも、同梱チュートリアルの漱石『こころ』ファイルのように、両方を1つのExcelファイル内に入力することをお勧めしています。
テキストファイル(分析対象ファイル)と対応する外部変数ファイルを準備する必要があります。ここで「対応する」というのは、ケース数やケースの順番が同じということです。例えば、アンケート調査の自由回答項目を分析する時に外部変数を用いたい場合、次のような外部変数ファイルを準備する必要があります。なお、外部変数ファイルは、CSV形式かタブ区切り形式で保存する必要があります。
|
テキストファイル
|
外部変数ファイル
|
||||||||||||||||||||||
|
|
この場合、テキストファイルではそれぞれの回答が改行で区切られているので、KH Coderは「段落」として各回答を認識しています。したがってこの場合、外部変数を読み込む際には、「読み込み単位」として「段落」を選択します。もしも回答者数が、テキストファイルと外部変数ファイルとで食い違っていると、エラーメッセージが表示されて読み込みが中断されます。
なお、100や200といった数の外部変数を読み込むと、操作に支障が出る場合があるかもしれません。内部処理には一切問題ないのですが、GUI(操作画面)の都合で、「コーディング」「外部変数とのクロス集計」コマンドの操作が厳しくなるかもしれません。現状では、10~20程度までがお勧めです。
読み込んだ外部変数はどうやって使うのですか?
「主な機能と分析手順」のページで解説している「段階1」では、例えば男性・女性の回答にそれぞれ特徴的な語をリストアップしたり(関連語探索コマンド)、年代ごとに特徴的な語をプロットすることができます(対応分析コマンド)。対応分析コマンドでは、読み込んだ外部変数のリストからマウス操作で1つ変数を選んで分析を行えます。関連語探索コマンドでは、「<>変数名-->値」のように入力することで、特徴的な語のリストアップを行えます。例えば「<>性別-->男性」のように入力すれば、「性別」変数の値が「男性」のケースに特徴的な語がリストアップされます。
次に分析の「段階2」では、コーディングの結果を集計する際に、男女別に集計して男女の違いを見るといったことが可能です(外部変数とのクロス集計コマンド)。また、コーディング結果を使った対応分析によって、コードと変数の値をプロットして、互いの関係を見ることができます(対応分析コマンド)。
その他にも、コーディングルール中で「<>変数名-->値」のように記述することで、外部変数をコーディングに利用することもできます。また、「コンコーダンス」や「文書検索」で開く「文書表示」画面の下部に、読み込んだ外部変数の値が表示されます。よって、回答者ID(のようなもの)を外部変数として読み込んでおくと、確認が楽になる場合があるでしょう。
なお、「女性が1、男性が2」といった数字のコードが、外部変数ファイルに入力されている場合もあるかと思いますが、このままではコーディングルールやKH Coderの画面表示が少し分かりにくくなってしまいます。そんな場合には、「値ラベル」として「男性」「女性」のような文字列を入力することで、「<>性別-->男性」のように指定できるようになります。
※余談ですが、既にチュートリアルを一通りフォローされた方ならお気づきの通り、外部変数の利用法というのは、チュートリアルにあった「見出し」の利用法と非常に似通っています。実際、「見出し」というのは特殊な形の外部変数として、KH Coderの内部で扱われています。
値ラベルの入力が面倒なのですが、なんとかなりませんか?
マウスとキーボードを交互に使いながら、値ラベルを入力していく作業は、確かにいくぶん面倒です。同じ値ラベルを複数のプロジェクトに入力するような場合には、SQL文を利用すると多少は楽になるかもしれません。「ツール」「SQL文の実行」コマンドを使って、以下のようなSQL文を実行すると、複数の変数・値に一気にラベルを貼ることができます。(SPSSで言うところの「value labels」シンタックスのようなものです)
「( '性別', '1', '女性' )」という1行が、「性別」という変数の値「1」に「女性」というラベルを貼る、という意味を表します。この部分には必要なだけ行を追加することができますが、最後の行末だけが「;」で、それ以外の行末は「,」であることにご注意下さい。この部分を編集した上でテキストファイルに保存しておけば、何度でも再利用できます。
| コーディングについて |
| 分析結果について |
普通は1つのクロス表に対して1つのカイ2乗値ですが、なぜKH Coderの「クロス集計」には複数のカイ2乗値が載っているのですか?
公式入門書のpp. 87-89または、旧掲示板のこちらのスレッドや#1139をご覧ください。
なぜKH Coderの「クロス集計」では、パーセントの値を横に合計しても縦に合計しても100%にならないのですか?
公式入門書のpp. 87-89または、旧掲示板のこちらのスレッドや#1139をご覧ください。
対応分析の結果の読み取り方を教えてください。
チュートリアル・スライドの22ページ目をご覧ください。
原点(縦軸も0、横軸も0の位置)からの方向と距離に注目するのがポイントです。抽出語と変数(見出し)の位置が「近い」「遠い」といった解釈は、厳密に書くと誤りです。
対応分析のプロットにはいくつかの方式・流儀があります。ですが、どの方式であっても、原点からの方向と距離に注目する解釈の仕方であれば問題は生じにくいです。もう少し詳しくは、公式入門書の第7章・第13章に記載があります。あるいはこちらの論文や掲示板のこちらのスレッドもご参考になるかもしれません。 さらに詳しくは『対応分析の理論と実践』や『対応分析入門 ―原理から応用まで―』などの書籍がご参考になるかと思います。
対応分析の「成分」とは何ですか?
テキストを、外部変数の値や見出しによっていくつかのグループに分けると、グループごとに各語の出現傾向に違いが生じます。この違いをなるべく凝縮して、1つの軸、すなわち1つの数値の大小で表現しようとしたものが「成分」です。たとえば「成分1」のように、番号の小さい成分ほど多くの違いが凝縮されています。
各「成分」がどれくらい大きな違いを表現できているかということ、すなわち、その「成分」にどれくらい大きな違いを凝縮できたかを示す数値(小数)が、各成分に添えられています。この数値は「固有値」と言います。たとえば下図の場合、成分1の固有値が0.1417で、成分2の固有値が0.07となっています。
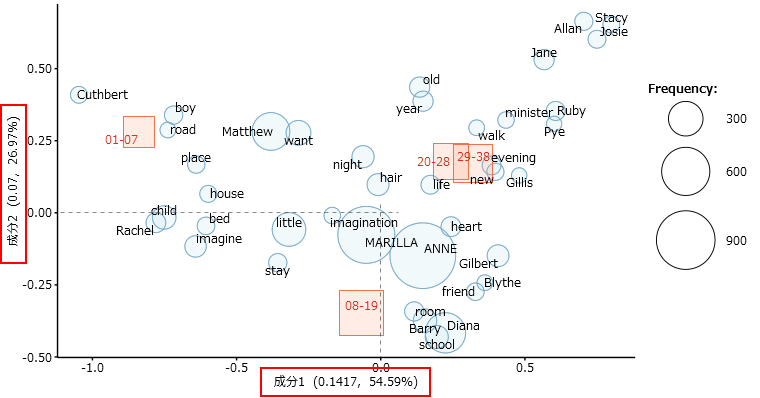
すべての「成分」の固有値を合計すれば、語の出現傾向の違いが全体でどれくらいあったのかという数値になります。この全体の数値に対して、各「成分」の固有値が占める割合が、パーセントで表示されています。つまり、すべての違いのなかで、その「成分」が表現できている違いが何パーセントかを示しています。
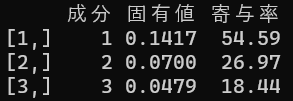
KH Coderの場合、すべての「成分」の固有値はコンソール画面に出力されています。今回の分析では、固有値の合計は0.1417 + 0.0700 + 0.0479 = 0.2596です。成分1で表現できている違いは、すべての違いのうち0.1417 ÷ 0.2596 × 100 ≒ 54.58パーセントとなります。(丸め誤差のせいで0.01%値がずれています)
なお「固有値」にはいくつか別名があり、「イナーシャ」とか「慣性」「主慣性」と呼ばれることもあります。
もう少し具体的な「成分」の計算法を、公式入門書の第13章に書いています。それよりももっと詳しく知りたい場合は、『対応分析の理論と実践』をお読みになると良いでしょう。
対応分析の結果、すべての語が1直線上に乗っていて、横軸も縦軸も「成分1」と表示されますが、これは何かの間違いですか?
使用した外部変数の値が「男性」「女性」とか、「前半」「後半」のように2種類(2カテゴリー)の場合は、成分が1つしか抽出されないと言いますか、結果を1次元(横軸のみ)で完全に表現できてしまいます。このことは公式入門書の第13章に書いている通りです。
したがって、結果をプロットするのに、2次元(横軸と縦軸)は必要ありません。本来は公式入門書の図13.3のように、水平に数直線を引いて、その上に抽出語とカテゴリー名をプロットすればよいのです。しかし水平に直線を引くよりも45度傾けた方が、抽出語やカテゴリー名のラベルを書き込むスペースがとりやすくなります。またプログラミング上の簡便さもあって旧版KH Coder(Ver. 3.Beta以前)では、やや強引なのですが、横軸縦軸ともに成分1(おなじもの)とすることで、45度傾けていました。
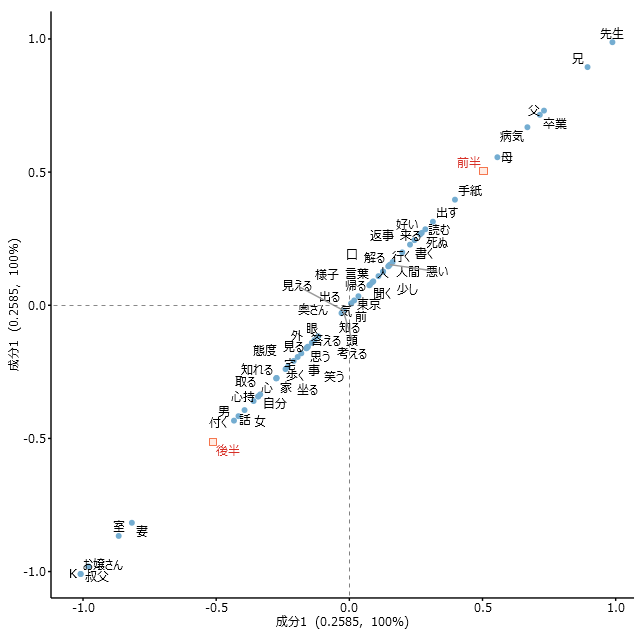
この結果は公式入門書の図13.3と同じものです。違うのは、図13.3を45度傾けているという点だけです。したがって、とくに何か間違っているとは開発者として考えていません。また公式入門書の図13.3とまったく同じように解釈できます。ただし、この図をそのまま論文に貼り込む場合には、以上のようなことを説明する必要があるでしょう。そうしないと「どうして2次元の図なのに、結果は1次元なのか(どうして1直線上にすべての語が乗っているのか)」「縦軸も横軸も『成分1』とはどういうことか」というような疑問を読者がいだくのは自然なことでしょう。
そうした(やや苦しい)説明をしたくなければ、最新のKH Coder ver. 3 正式版を使用するか、代わりに共起ネットワーク(下図)や特徴語の表を使うことが考えられます。
※横軸縦軸ともに「成分1」とすることで45度傾ける上図のような出力は、最良の表現というわけではありませんでしたし、「間違い」と評価する方もいらっしゃいますので、現在のKH Coderでは改訂済みです(その1・その2)。改訂後の出力であれば「間違い」とは言われないようです。
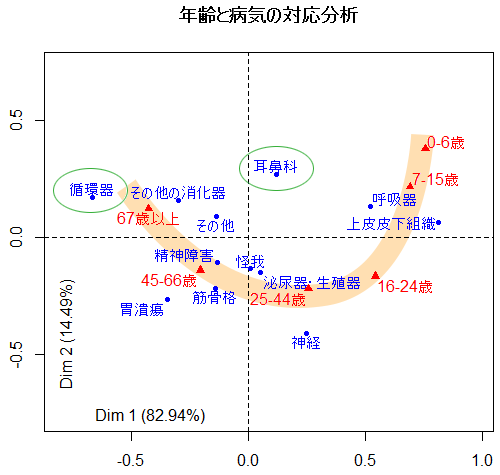
対応分析の結果を示したところ「馬蹄形ではないか」と指摘されました。「馬蹄形」の結果には何か問題があるのでしょうか?
多くの抽出語や変数(見出し)が、放物線のような形に並ぶプロットは「馬蹄形」(Arch pattern or "horseshoe" pattern)と呼ばれることがあります。たとえば下図のような形です。
( 出典:『対応分析入門 ―原理から応用まで―』第3章掲載のデータを用いて作成)
こうした場合でも、基本的には(1つ上の項目で述べた)通常の解釈が可能です。たとえば「循環器」は(1)原点から遠くに離れており、(2)原点から見て「67歳以上」の方向にあることから、「循環器の病気は67歳以上の人に特徴的である」ことが分かります。
ただし、こうした形のプロットを解釈するときには気をつける点もあります。1つは、「67歳以上」から「0-6歳」にかけての年齢による変化が、直線上ではなく、曲線(放物線)の上に描かれているということです。1つの軸(この場合は年齢)による影響がとても大きい時に、こうした「馬蹄形」があらわれがちです。
そしてもう1つ、こうした場合、「67歳以上から0-6歳にかけての変化」という軸に乗らない病気は、放物線上にも乗りません。上の図では「耳鼻科」が放物線から大きく外れています。耳鼻科は「67歳以上」にも「0-6歳」にも多いというめずらしい病気であったためです。
結論として、「馬蹄形」は必ずしも悪いものではありませんが、解釈する時に以上の2点に注意が必要と考えます。こうした点についてさらに詳しくは、『対応分析入門 ―原理から応用まで―』のpp. 28-31や、Correspondence Analysis in Practice 2nd ed. のpp. 126-128を参照してください。
対応分析の結果(語の座標)を取り出して、他のソフトでプロットを作り直すには?
KH Coder 3では多次元尺度構成法や対応分析の結果をCSV形式で保存できるようになりました。CSV形式で保存したファイルを、他のソフトでご利用ください。共起ネットワークの実線と点線の違いを教えてください。
自動的にグループ分け(サブグラフ検出)を行なった時、同じグループに含まれるノード(語)は実線で結んでいるのに対して、異なるグループに含まれるノードは破線で結んでいます。
それだけのことですので、深遠な意味があるわけではなく、単にグループ分けの結果を見やすくするための小さな工夫です。
共起ネットワークではどのように共起関係の強さを図っているのですか? Jaccard係数とは何ですか?
共起ネットワークでは、特に設定を変更していなければJaccard係数というものを使って、共起の強さを測っています。この係数について詳しくは、『実例 クラスター分析』という書籍がお勧めです。
私も簡単な説明スライドを作っていますので、よろしかったらご覧ください。
共起ネットワークに描かれている共起関係の強さを数値で確認するには?
KH Coder 3では「係数を表示」というオプションを追加したので、こちらをお使いください。係数を一覧表示したり保存することについては、旧掲示板のこちらのスレッドをご参照ください。こちらもご参考になるかもしれません。
共起ネットワークに出てこない語があります。
データ中には多く出現していても、線(edge)として描くべき共起関係がなかった語(他の語とよく一緒に使われているという関係が無かった語)は、ネットワークに出てきません。重要な語がネットワーク上に現われない場合、比較的弱い共起関係も描かれるように、デフォルトの上位60から上位100程度に描画する共起関係を増やしてみるとよいかもしれません。場合によっては上位200から上位300程度に増やすこともできますが、この場合は線(edge)がこんがらがってしまうのを防ぐために、「最小スパニングツリーだけを描画」すると良いでしょう。
根本的な解決のためには、共起ネットワークではなく、階層的クラスター分析・多次元尺度構成法・自己組織化マップを使うとよいでしょう。
共起ネットワークの語の位置を編集するには?
共起ネットワークの語の配置は、ネットワークをなるべく読み取りやすいようにという基準で決まっています。したがって、配置にはあまり意味がありませんので、好きなように微調整していただいて問題ありません。
なおKH Coder 3では共起ネットワークをPajek形式やGraphML形式で保存できるようになりました。これらの形式で保存したファイルをPajek、Cytoscape、Gephiなどのソフトウェアで開いて、編集していただくこともできます。
プロットをIllustratorで編集するには?(Windows環境)
たとえば対応分析のプロットで、重なってしまった語のラベル位置をなおしたり、ラベルのフォントサイズを変更したりといった編集を行いたい場合があるでしょう。Windows環境では、Adobe IllustratorKH CoderのプロットをIllustratorで編集する場合には以下の手順がスムーズなようです。WindowsのCS6環境でテストしました。
- KH Coderのプロット保存画面で、EPSまたはPDF形式を選択して保存します。※2.b.28でPDF形式での保存に対応します。
- 保存したファイルをAcrobat
で開き、Acrobatから「名前を付けて保存」で、EPS形式で保存します。
- Illustratorで、Acrobatから保存したEPSファイルを開きます。
Illustratorでの編集
1度Acrobatで開いてEPSで保存するというのがカギのようです。この際に、オプションで「ソースと同じ(カラーマネジメントなし)」を選択しておくと、色味が維持されます。
なお、KH Coderから保存したPDFファイルをそのままIllustratorで開くと、文字化けはしないものの、フォントがアウトライン化されて編集が少しやりにくくなってしまう様子です。
| WordMinerとKH Coderとの連携・併用 |
併用することにどんな利点があるのですか?
■KH Coder側から見ると:
KH Coderを既にお使いの方には、対応分析(数量化III類)をはじめとする記述的多変量解析を行うための優れたソフトウェアとして、WordMinerをご利用いただけます。極端な書き方をすると、WordMinerをテキストマイニングのソフトとしてではなく、統計解析ソフトとして使わせていただく形になります。
■WordMiner側から見ると:
WordMinerを既にお使いの方には、分かち書きのための選択肢の1つとしてKH Coder(茶筌・MeCab・etc.)をお使いいただけます。WordMinerで言うところの「構成要素変数」として、KH Coder(茶筌・MeCab・etc.)による語の抽出結果をお使いいただけます。これによって、WordMiner上で品詞情報を利用することができるようになります。例えば、「名詞だけを使って分析をしてみよう」「形容詞だけを使って分析をしてみよう」といったことがWordMiner上で容易に行えます。
それに加えて、KH Coderの柔軟なコーディング機能もお使いいただけます。KH Coderによるコーディングの結果も、「構成要素変数」としてWordMiner上でお使いいただけます。
■「連携・併用」とは:
ここで言う「併用」とは、WordMiner上で、KH Coderによる語の抽出(分かち書き)結果やコーディング結果を利用することを指しています。WordMiner上で「構成要素変数」として利用・分析するということです。
処理手順は以下のようになります:
- KH Coderでテキストから語を抽出(分かち書き)する
- 「プロジェクト」→「新規」でExcelファイルを指定
- 「前処理」→「前処理の実行」から前処理(語の抽出)を行う
- KH Coderによる語の抽出結果をファイルに書き出す
- 「ツール」→「『文書x抽出語』表の出力」→「不定長CSV(WordMiner)」をクリック
- 開いた画面で「集計単位の選択」部分を「H5」に設定
※KH Coderは1つ1つのセルを、H5単位とみなします。 - 「OK」をクリックして、名前を付けてファイルを保存する
(ここでは仮に「抽出結果.csv」と名前をつけたことにする) - WordMinerでプロジェクトの新規作成を行う
- WordMinerで分析対象のExcelファイルを読み込む
- WordMinerで、KH Coderによる語の抽出結果を読み込む
- 「データの読み込み」から、先程保存した「抽出結果.csv」を選択して読み込む
(これによって「名詞」「サ変名詞」「形容動詞」...といった原始変数が読み込まれる) - 「変数の生成」→「●構成要素変数を生成」→「変数の種類を変更し、新しい変数を生成」を選択して、「次へ」をクリックする。そして、「名詞」「サ変名詞」「形容動詞」などにチェックを入れて構成要素変数を生成
※KH Coderによって既に分かち書きが行われているので、再度WordMiner上で分かち書きを行う必要はありません。よって、「変数の種類を変更」するだけで、構成要素変数を作成できます。
| カスタマイズや自動化 |
64bit版のWindows環境で2GBを超えるメモリを使用するには?
現在のWindows版パッケージには32bit版のMySQLを同梱しています。よってMySQLに関しては64bit版のWindows上でも、2GBまでしかメモリを利用できません。ここで、手順はやや煩雑なのですが、ご自身で64bit版のMySQLをインストールしていただけば、2GB以上のメモリを使うことができます。
MySQLがより多くのメモリを使用できれば、「前処理効率化のためにデータをRAMに読み出す」設定が有効に働き、前処理が比較的短い時間で終わる場合があるでしょう。また64bit版のMySQLでは、32bit版に比べて10%ほど処理時間が短縮されるようです。
MySQLを64bit化する手順は以下のようになります:
- 64bit版のMySQLをインストール・設定する。この際、「max_heap_table_size」の値を搭載メモリにあわせて大きくしておく。
- KH Coderの設定ファイル「config\coder.ini」をテキストエディタで開き、「all_in_one_pack」の行を「1」から「0」に変更する。また「sql_username」「sql_password」「sql_port」を、インストールした64bit版MySQLにあわせて修正する。
データの規模によっては焼け石に水かもしれませんが、64bit環境でめいっぱいメモリを積んでいるような場合には、試してみる価値があるかもしれません。
※Rに関しては、現在のWindows版パッケージには64bit版と32bit版の両方を同梱しており、64bit環境では自動的に64bit版が動くようになっています。したがって、Rを使った多変量解析がメモリ不足で止まるケースは減っているかと思います。もちろん限界はあるのですが。
コマンドラインから新規プロジェクト作成・共起ネットワーク保存を自動実行するには?
こうした自動化を行なうためのプラグイン見本として「plugin_jp\auto_run.pm」を同梱しています。使用例を掲示板のこちらのスレッドに書いています。このプラグインについての詳しい解説は、書籍『Rのパッケージおよびツールの作成と応用』をご覧ください。
KH Coderのソースコードを解読するコツはありますか?
行番号や仕様がその後少し変更になっていますが、掲示板への投稿「ソースコードの編集」がご参考になるかもしれません。
| その他 |
『言語研究のための統計入門』(くろしお出版)の「練習問題」や「実例研究」では、KH Coderで同じ操作を何十回も繰り返さねばならないのですか?
KH Coder操作方法の「別解」として、同じ作業を繰り返さなくてよい方法を別ページでご紹介しています。
KH Coderを使った計量テキスト分析の見本になるような論文は?
「KH Coderの本」第2版・第8章で研究事例のレビューを行ないました。 「たくさん研究事例はあるけど、どれがおもしろくて参考になるの?」という疑問に、ある程度お答えできたと思います。優れた研究事例のレビューを通じて「どのようにKH Coderを利用すれば学術的意義のある発見につながりやすいのか」を書かせていただきました。ほかには、どちらもKH CoderではなくAutocode(リンク1・リンク2)というソフトを使っているのですが、以下の2つもお勧めできます。
- 太郎丸博 1999 「身の上相談記事から見た戦後日本の個人主義化」 川端亮編著 『非定型データのコーディング・システムとその利用』平成8年度~10年度科学研究費補助金(基盤研究(A)(1))(課題番号08551003)研究成果報告書 39-154 PDF File
- 川端亮 1999 「真如苑における霊位向上」 川端亮編著 『非定型データのコーディング・システムとその利用』平成8年度~10年度科学研究費補助金(基盤研究(A)(1))(課題番号08551003)研究成果報告書 PDF File
前者の論文(太郎丸 1999)は内容も興味深いですし、問題の提示→その問題へのアプローチに適したデータと方法→分析結果→考察という、オーソドックスな論文としての構成がしっかりしていて勉強になります。後者の川端(1999)は、個別のインタビューからは解明できなかった「霊脳」について、自由記述の計量テキスト分析を行うことで手がかりを掴んでいます。計量テキスト分析が実際の研究にどのように寄与するのかということについて、その一端を示していると言えるでしょう。
次にKH Coderを使ったものでは、自分の携わったもので僭越ですが、まずはこれらが読みやすいかと思います。自由回答データの探索的な分析を行なっています。
- 樋口耕一 2021 「誰がなぜ改憲に賛成・反対しているのか ―自由記述データの計量テキスト分析から―」 辻大介編 『ネット社会と民主主義 ―「分断」問題を調査データから検証する―』 有斐閣 95-112 Amazon
- 阪口祐介・樋口耕一 2015 「震災後の高校生を脱原発へと向かわせるもの ―自由回答データの計量テキスト分析から―」 友枝敏雄編 『リスク社会を生きる若者たち ―高校生の意識調査から―』 大阪大学出版会 186-203 Amazon
- 川端亮・樋口耕一 2003 「インターネットに対する人々の意識 ―自由回答の分析から―」 『大阪大学大学院人間科学研究科紀要』 29: 163-181 PDF File
このほか「KH Coderの本」の第5章・第6章で示した分析事例もご参考にしていただけるかと思います。ここに挙げた分析事例の多くで、「主な機能と分析手順」ページで触れた「2段階での分析」を行っています。
KH Coderの設計思想を書いた論文は?
以下の文献に、「こういう方法での分析を行うためにKH Coderを作製した」ということを書いています。テキスト型データの分析方法を提案し、その方法での分析を実際に行うために、KH Coderを作製したという形です。
- 樋口耕一 2004 「テキスト型データの計量的分析 ―2つのアプローチの峻別と統合―」 『理論と方法』(ISSN:0913-1442) 19(1): 101-115 PDF File
- 樋口耕一 2020 『社会調査のための計量テキスト分析 ――内容分析の継承と発展を目指して 第2版』 ナカニシヤ出版 サポートページ Amazon
英語でもある程度までは書いています。
- Koichi Higuchi 2016 "A Two-Step Approach to Quantitative Content Analysis: KH Coder Tutorial Using Anne of Green Gables (Part I)" Ritsumeikan Social Science Review, 52(3): 77-91 PDF File
- Koichi Higuchi 2017 "A Two-Step Approach to Quantitative Content Analysis: KH Coder Tutorial Using Anne of Green Gables (Part II)" Ritsumeikan Social Science Review, 53(1): 137-147 PDF File
技術的な設計思想は文書になっていません。強いて書くならば、以下のようなことを考えながら作製しています。
- 処理速度向上よりも、柔軟に機能を追加できる構造の維持を優先する
- 検索やソートなどは極力MySQLに任せる
- 多変量解析や統計処理は極力Rに任せる
- インターフェイスとロジックはできるだけ分離する
KH Coderの正式な表記は何ですか?
KH Coderの正式な表記は「KH Coder」です。「KH-Coder」「KH_coder」「KHCoder」「KH CODER」「KHコーダー」「KH Corder」などではなく、「KH Coder」です。ただし縦書きの文書中でアルファベットを「立てる」場合には「KH CODER」とすべて大文字で表記していただくとすわりが良いでしょう。
※強いこだわりがあるわけでもないのですが、もしかすると迷われる方もいらっしゃるかと思いまして…。
KH Coderの「KH」とは何の略ですか?
KHは「Kawabata Higuchi」の略だという説の他に、「Keystone Hammer」「Knowledge Harvest」「Knight Hawk」などの略だという説もありますが、最初の説がもっとも有力です。なお「Koichi Higuchi」の略だという説は誤りです。
[ KH Coder ]