|
わざわざ別の統計解析ソフトウェアを使わなくても、ある程度まではKH Coder上でデータの様子を見ることができるように、以下のような解析機能を準備しました。解析には、統計計算とグラフィックスのための環境「R」を内部で利用しています。
※以下のスクリーンショットには一部開発中のバージョンが含まれています。
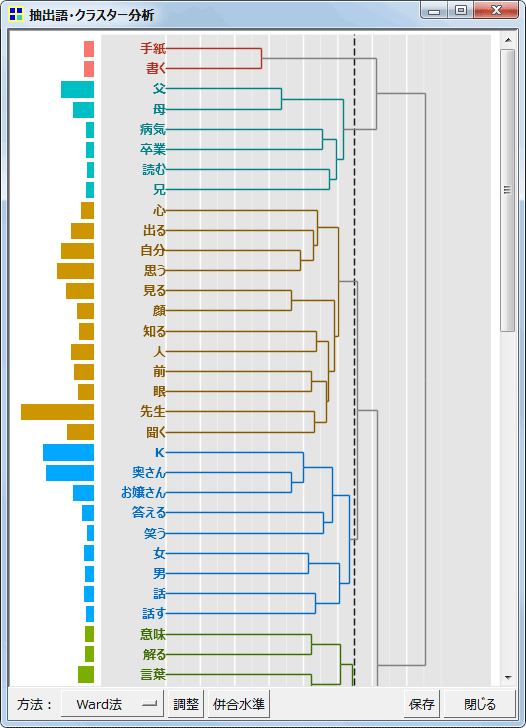
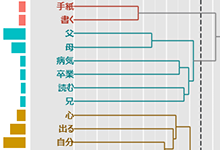
階層的クラスター分析
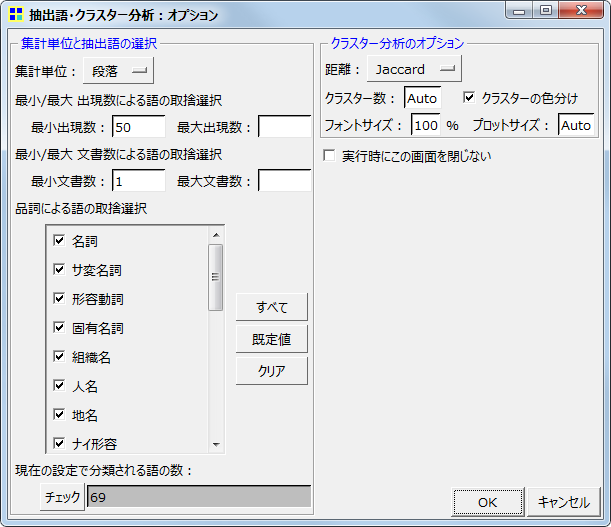
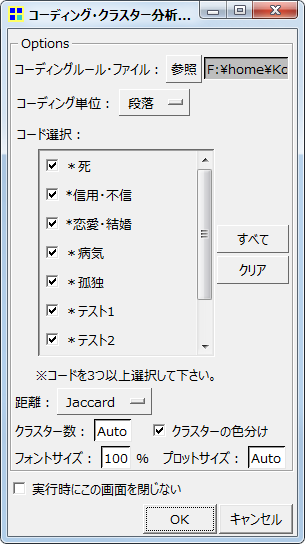
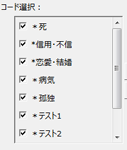
抽出語の階層的クラスター分析を行い、デンドログラムを表示します。抽出語だけでなくコーディング結果(コード)についても、同じように分析を行えます。
 |
|
|
|
 |
|
New! デンドログラム
|
|
抽出語は出現数や品詞で選択
|
|
コードはチェックボックスで直接選択
|
指定されたクラスター数に全体を分割し、その結果を色分けによって表示します。色分けせずに、四角形で各クラスターを囲むこともできます。
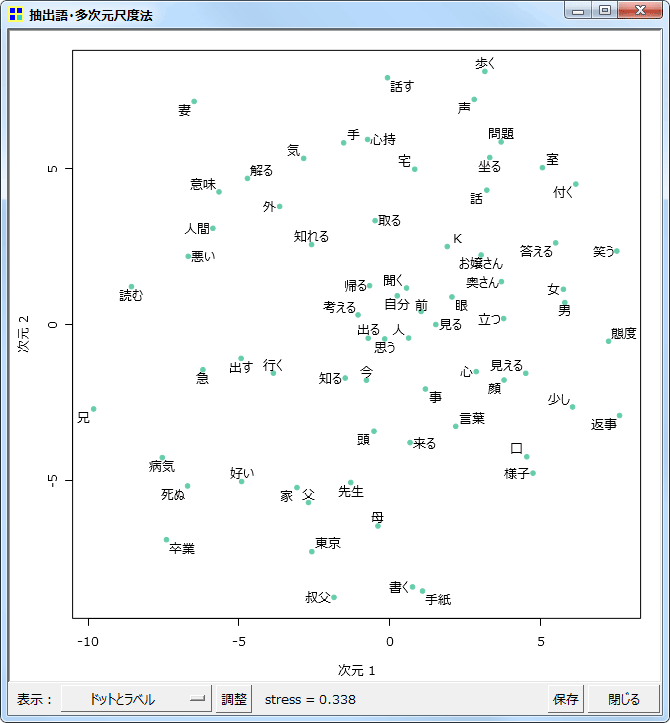
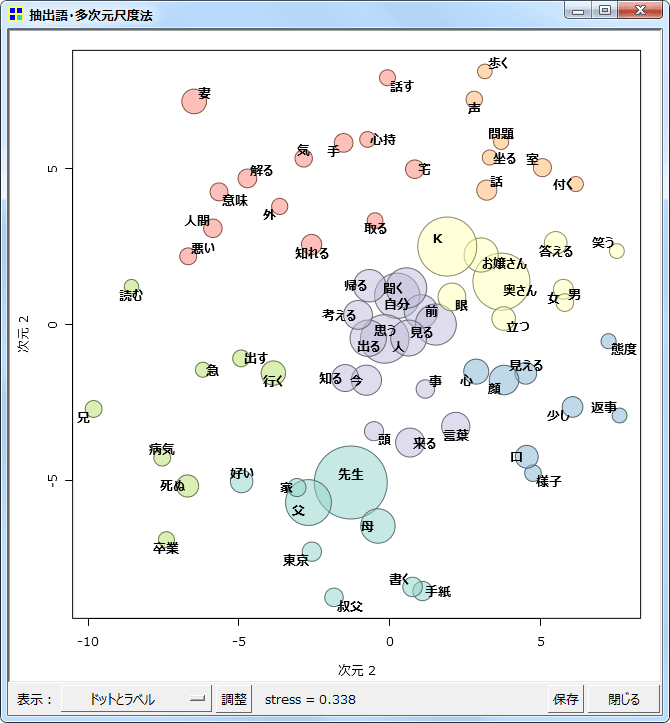
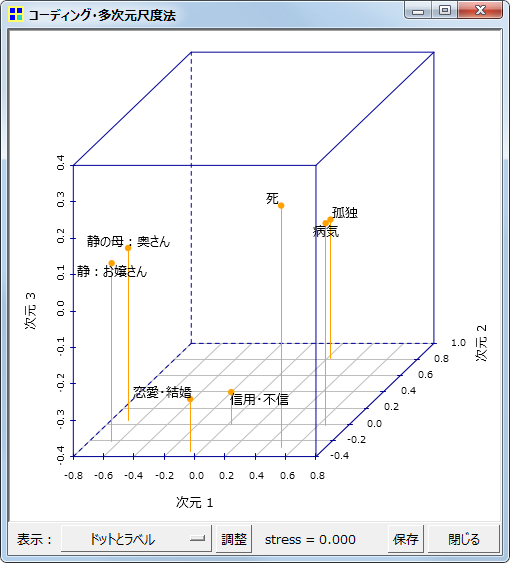
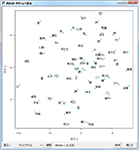
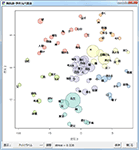
多次元尺度構成法(MDS)
同じく抽出語またはコードを用いての、多次元尺度構成法です。
 |
|
 |
|
|
|
2次元の解
|
|
New! クラスタリングと色分け
|
|
3次元の解
|
1次元から3次元までの解を表示することができます。布置する語やコードの数が多い場合には、2次元解の表示がもっとも読み取りやすいでしょう。
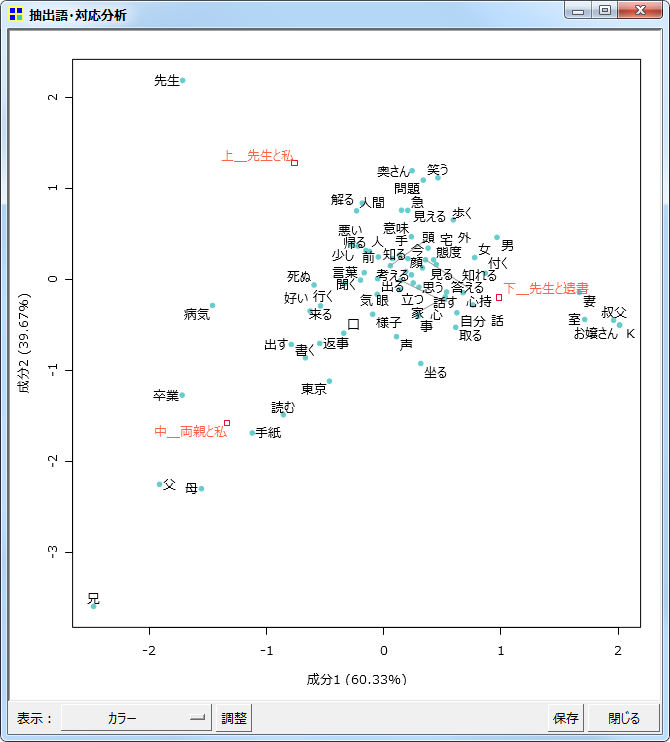
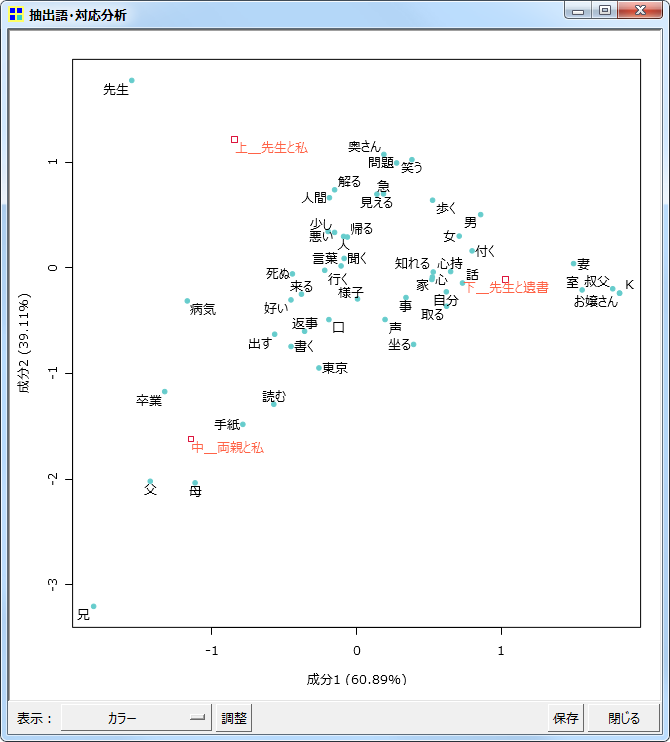
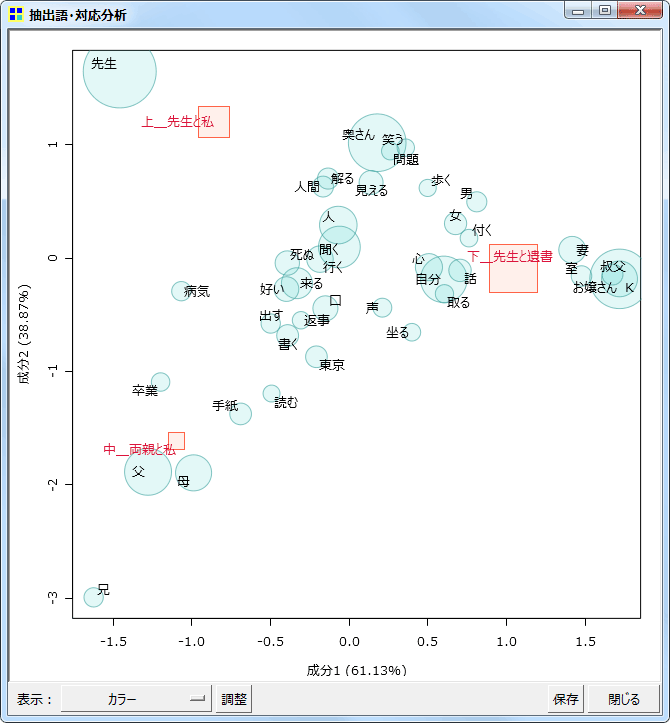
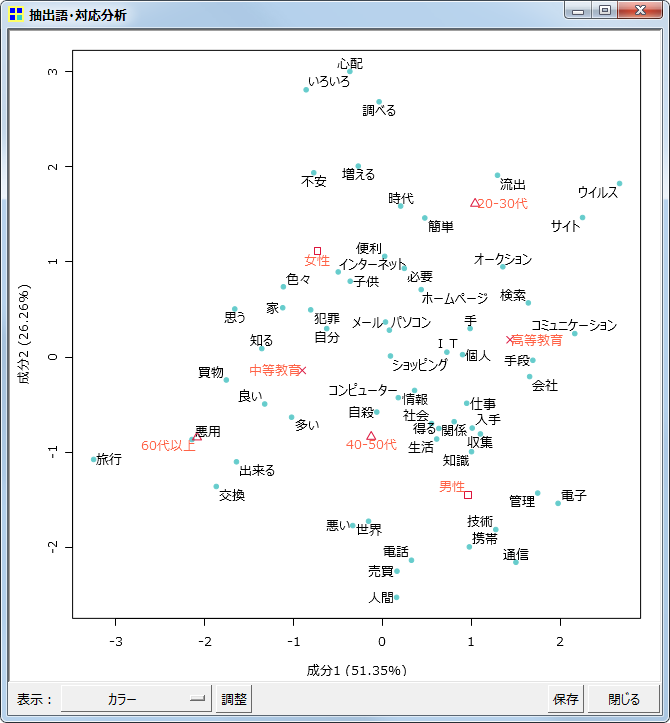
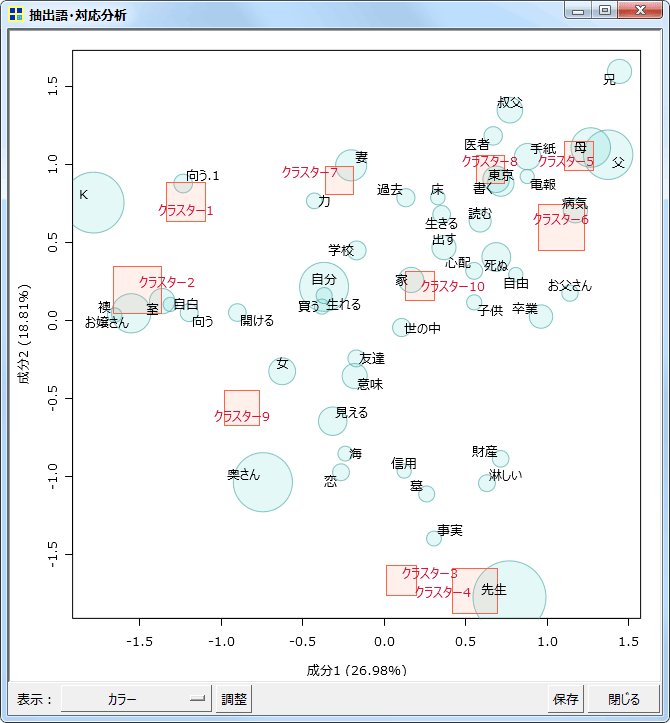
対応分析
同じく抽出語またはコードを用いての、対応分析です。
|
|
|
|
|
|
|
同時布置図
|
|
差異が顕著な語に注目(上位50語)
|
|
グレースケール印刷用
|
|
|
|
|
|
|
|
New! バブルプロット
|
|
複数の外部変数を用いた多重対応分析
|
|
|
分析結果として、このような2次元のプロットが表示されます。いくつの成分を抽出し、どの成分をそれぞれx軸・y軸に用いるかも設定できます。
ただしKH Coderによる結果表示はこの画面だけなので、2つだけでなくより多くの成分を抽出したりといった、詳細な探索を行うには少々苦しいものがあるかもしれません。そうした詳細な探索にあたっては、例えば各成分の特徴を見やすい一覧表にまとめてくれる機能をはじめとして、充実した多次元データ解析の機能を持つWordMinerを、KH Coderと併用すると便利でしょう。
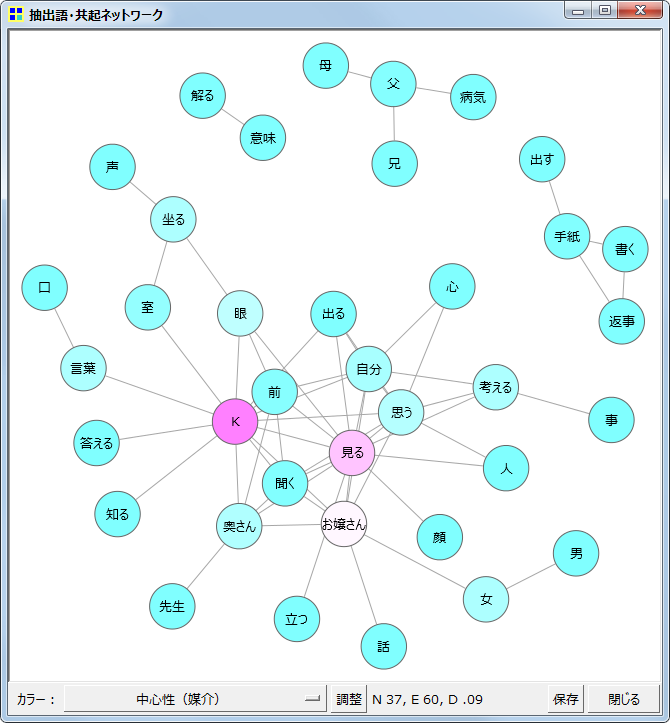
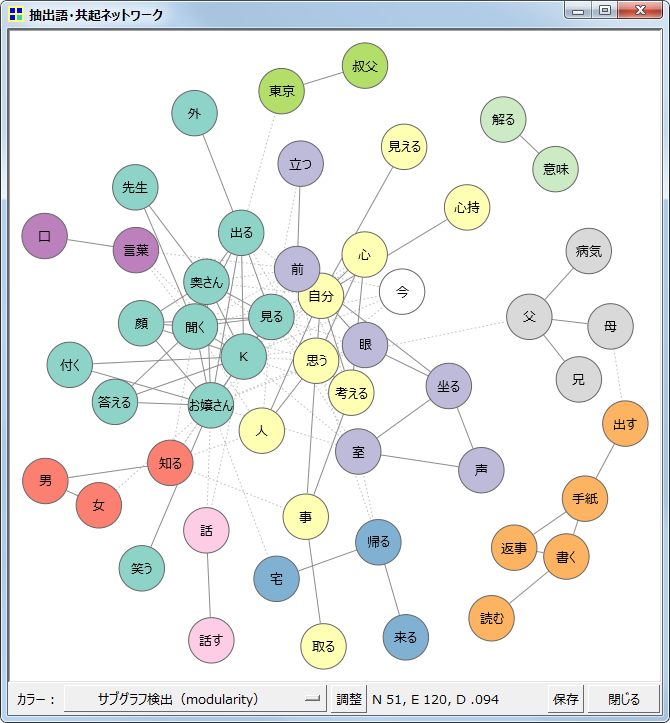
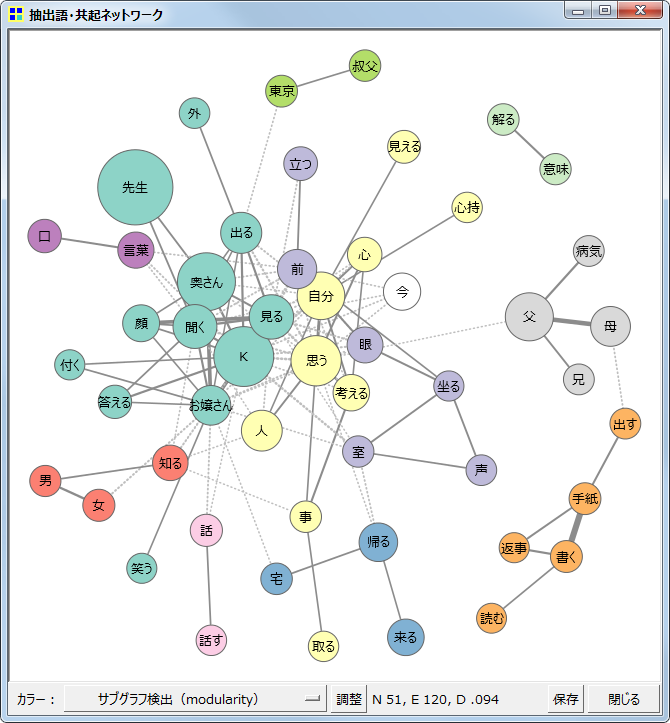
共起ネットワーク
抽出語またはコードを用いて、出現パターンの似通ったものを線で結んだ図、すなわち共起関係を線(edge)で表したネットワークを描く機能です。
 |
|
|
|
 |
|
共起の程度が非常に強いものだけを線で結んだ図
|
|
やや弱い共起関係も描画に含め、自動的にグループ分け(色分け)
|
|
出現数が多い語ほど大きく、また共起の程度が強いほど太い線で描画
|
上の左端の図では、ネットワーク分析で言う「中心性」にもとづいて色分けを行っています。水色・白・ピンクの順に中心性が高くなります。なお、この図は多次元尺度法(MDS)とは異なり、布置された位置よりも、線で結ばれているかどうかということに意味があります。したがって、単に近くに布置されているだけで線で結ばれていなければ、共起の程度が強いことを意味しません。
 |
|
|
|
 |
|
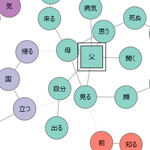
特定の語「父」と関連が強い語の共起ネットワーク
|
|
それぞれの語を小さめの円で描画 (なかば好みの問題ですが、それなりに印象が違います)
|
|
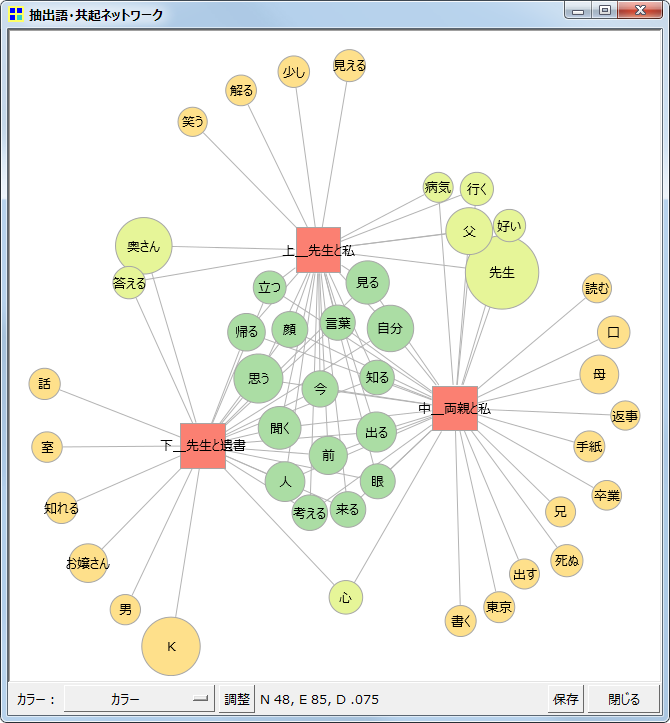
語と語ではなく、語と外部変数/見出しの関連を描いたネットワーク
|
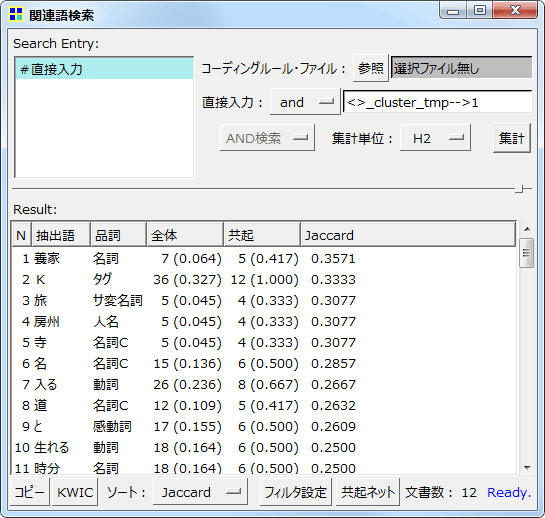
左の2つは、「父」という特定の語に注目して、(1)関連が強い語をリストアップし、(2)それらの語を用いて共起ネットワークを作成したものです。特定の語に限らず、特定のコードに注目することもできます。よって、アンケートの自由記述データを扱う場合であれば、「女性の回答の共起ネットワーク」「男性の回答の共起ネットワーク」をそれぞれ作成して比べるといったこともできるでしょう。※この機能は「共起ネットワーク」コマンドではなく、「関連語探索」コマンドから呼び出します。
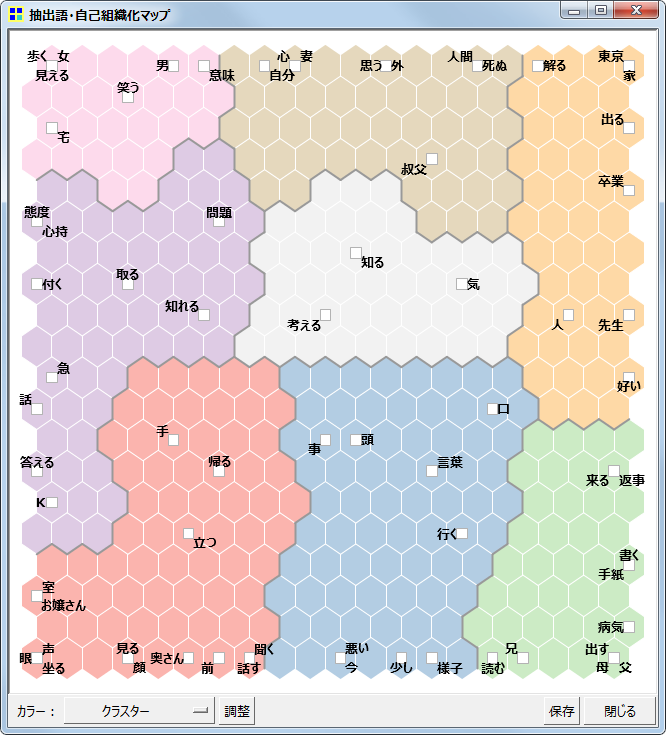
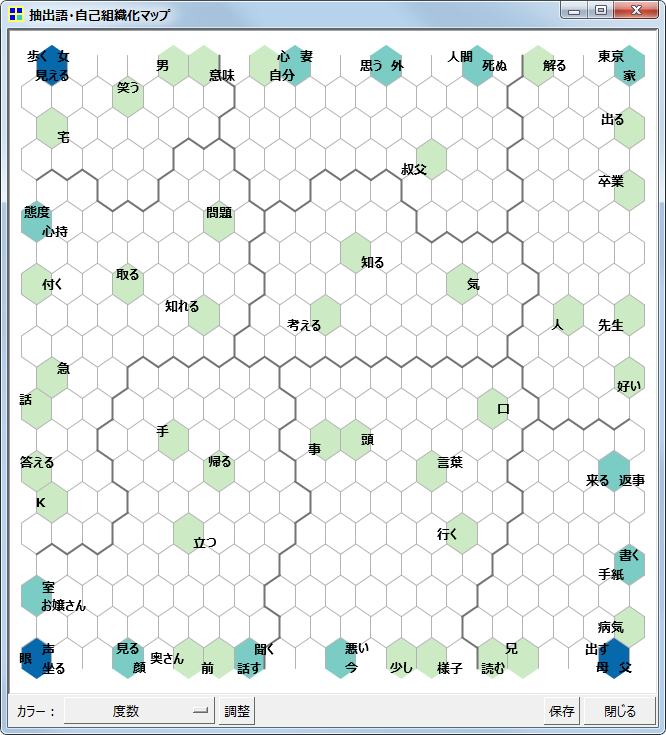
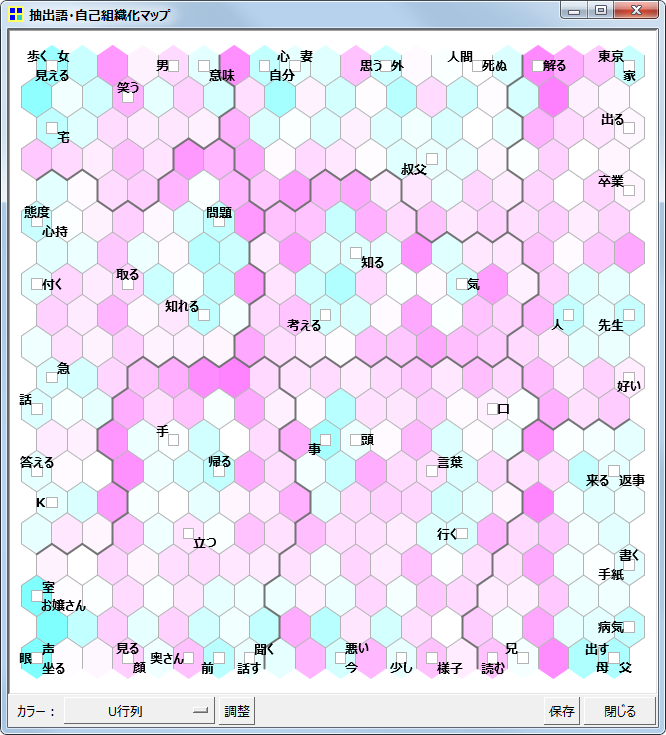
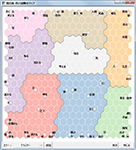
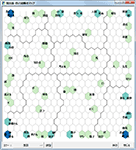
自己組織化マップ
抽出語またはコードを用いての、自己組織化マップです。
 |
|
 |
|
|
|
クラスター色分け
|
|
頻度のプロット
|
|
U-Matrix
|
デフォルトの設定では、学習に非常に長い時間を要するのでご注意下さい。
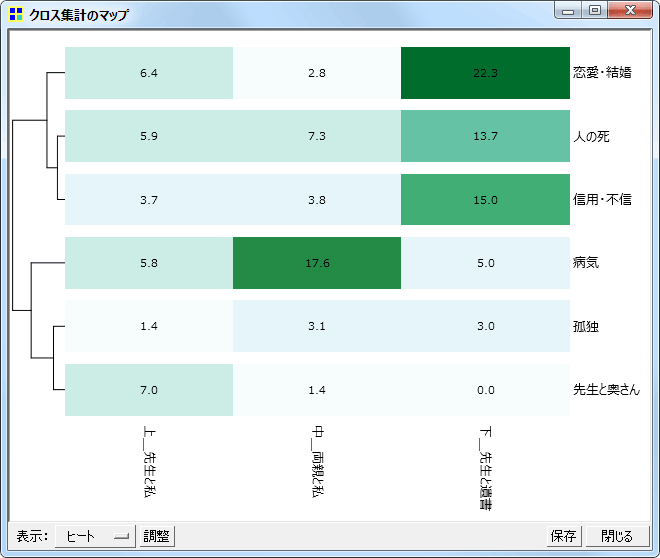
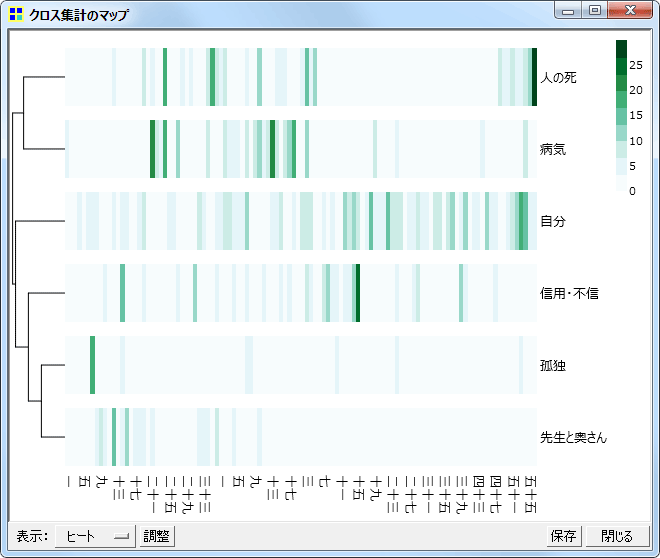
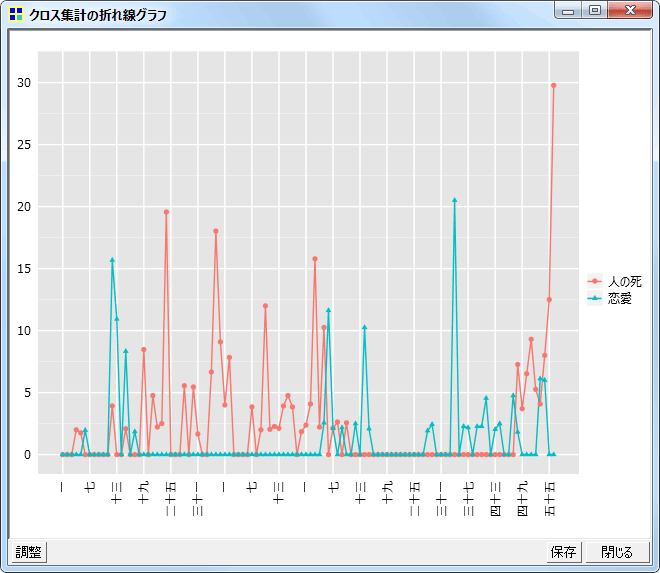
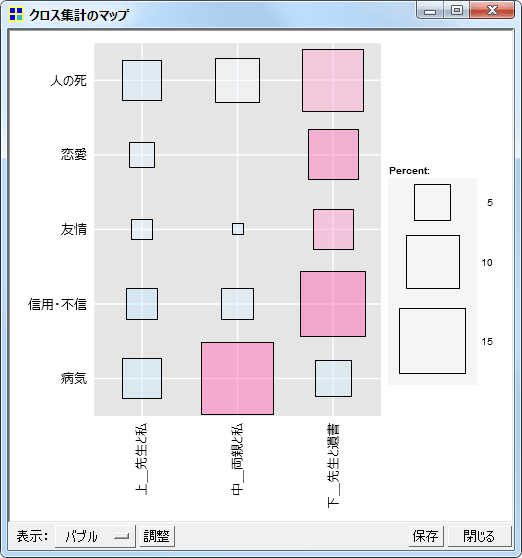
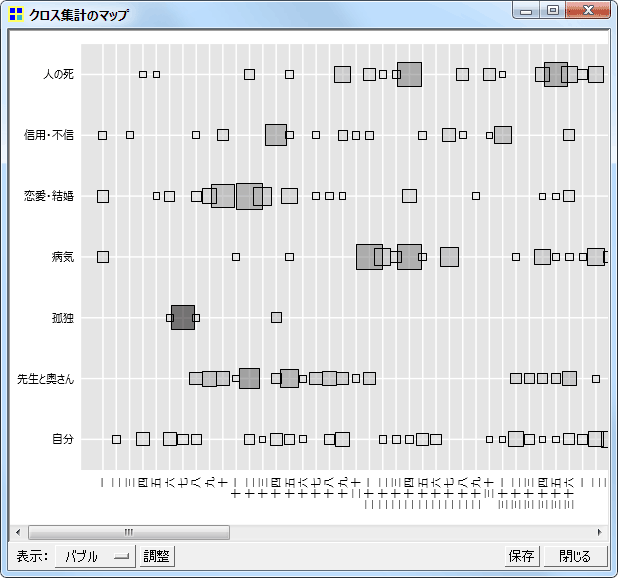
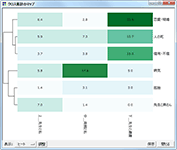
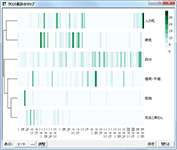
コードが多く出現している箇所
データ中のどの部分で各コードが多く出現しているのかを表現するプロットです。
 |
|
 |
|
|
|
New! ヒートマップ
(分割数小)
|
|
New! ヒートマップ
(分割数大)
|
|
New! 折れ線グラフ
|
|
|
|
|
|
|
|
|
|
|
|
|
New! バブルプロット
(分割数小・カラー)
|
|
New! バブルプロット
(分割数大・グレー)
|
|
|
この部分は、長い間「Excelでグラフを作って下さい」という形になっていましたが、やはり少し不便でした。特にいろいろな分析を試して結果を見たい場合には、KH Coder上ですぐにグラフを見られる方が便利だということで、これらの作図機能を準備しました。
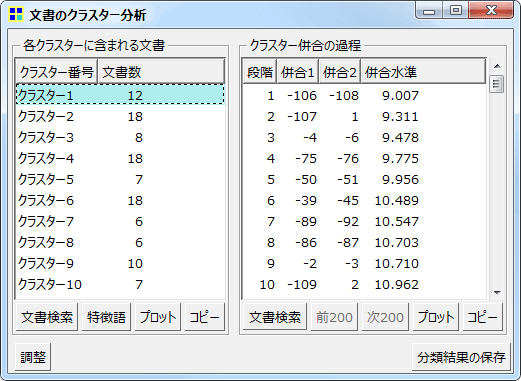
文書のクラスター分析
 |
|
|
|
 |
|
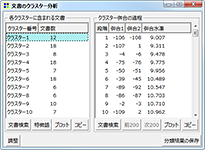
クラスター分析の結果画面
|
|
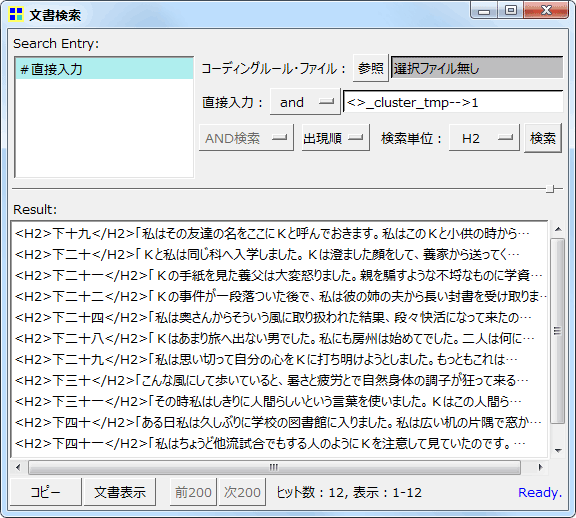
左の画面で「文書検索」をクリックすると、当該クラスターに含まれる文書の一覧を表示
|
|
一番左の画面で「特徴語」をクリックすると、当該クラスターに特徴的な語をリストアップ
|
クラスター分析の結果画面には、各クラスターにいくつの文書が分類されたかが表示されています。また1クリックで、選択中のクラスターに含まれる文書の一覧や(文書検索)、そのクラスターに特徴的な語(関連語探索)を表示できます。以下のようなプロットも表示できます。
 |
|
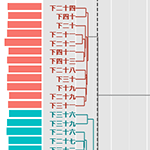 |
|
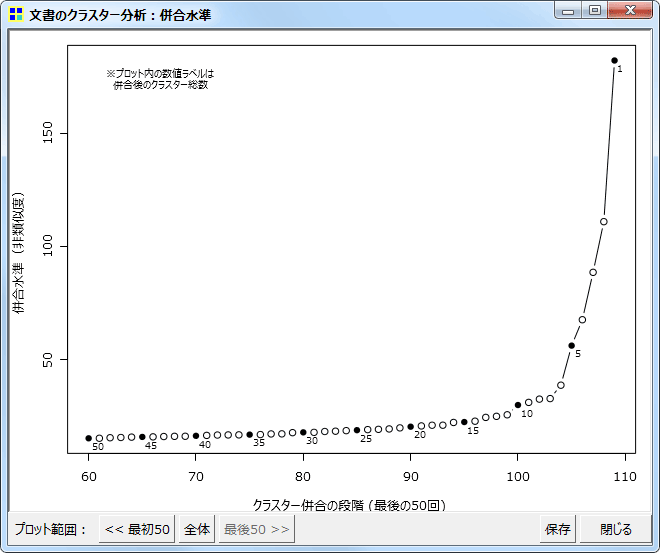
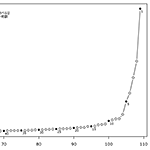
併合水準のプロット。クラスター数5付近から併合水準が急上昇。10でも少し上がっているので、この場合クラスター数は11が良いか。
|
|
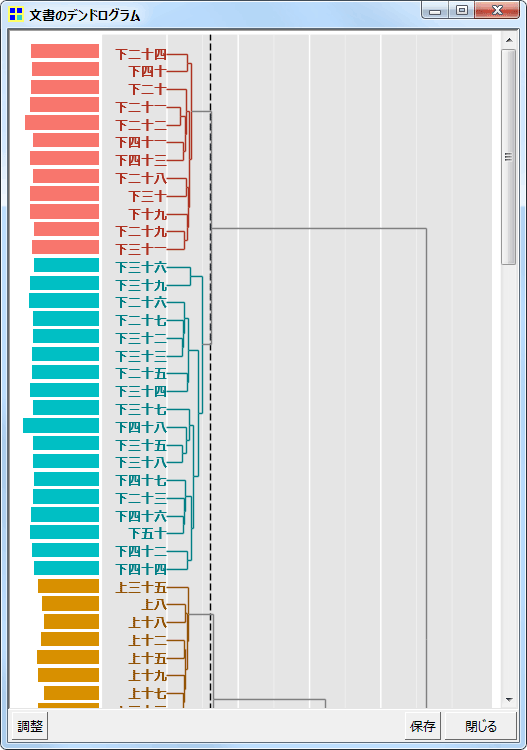
文書のデンドログラム。左の棒グラフは各文書の長さをあらわす。なお、文書数が500を超える場合、デンドログラムは表示不可。
|
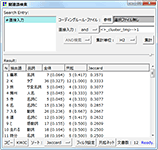
文書を分類した結果は、外部変数として保存することができます。この外部変数を使えば、各クラスターの特徴語の一覧を作成したり、対応分析を行なったりすることで、クラスターの内容を探索できます。
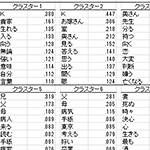 |
|
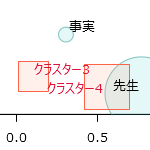 |
|
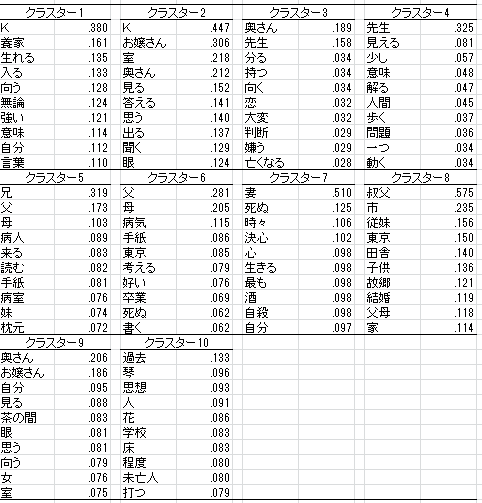
各ラスターの特徴語一覧。ここでは段落単位で計算。
|
|
対応分析では、各クラスターの特徴語だけでなく、どのクラスターとどのクラスターの内容が似通っているかも見やすい。
|
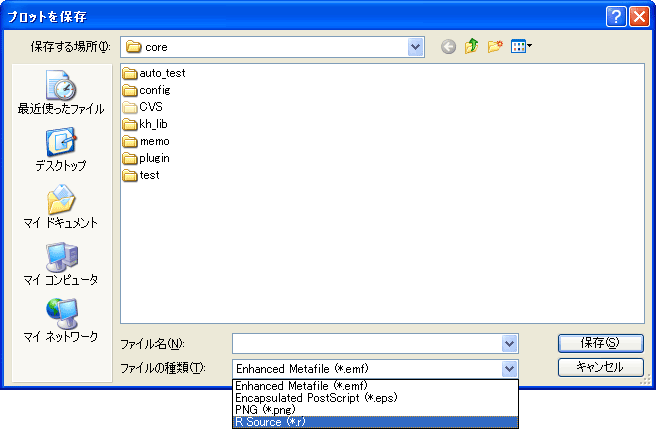
プロットの保存と活用
各プロット画面の「保存」ボタンをクリックすることで、プロットを4種類の形式で保存することができます。Word・PowerPoint等へ貼り付ける際はEMF形式、LaTeXで利用する場合はEPS形式、Webページに載せる場合などはPNG形式で保存すると良いでしょう。
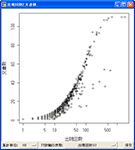 |
|
|
|
KH Coderでの表示
|
|
保存画面
|
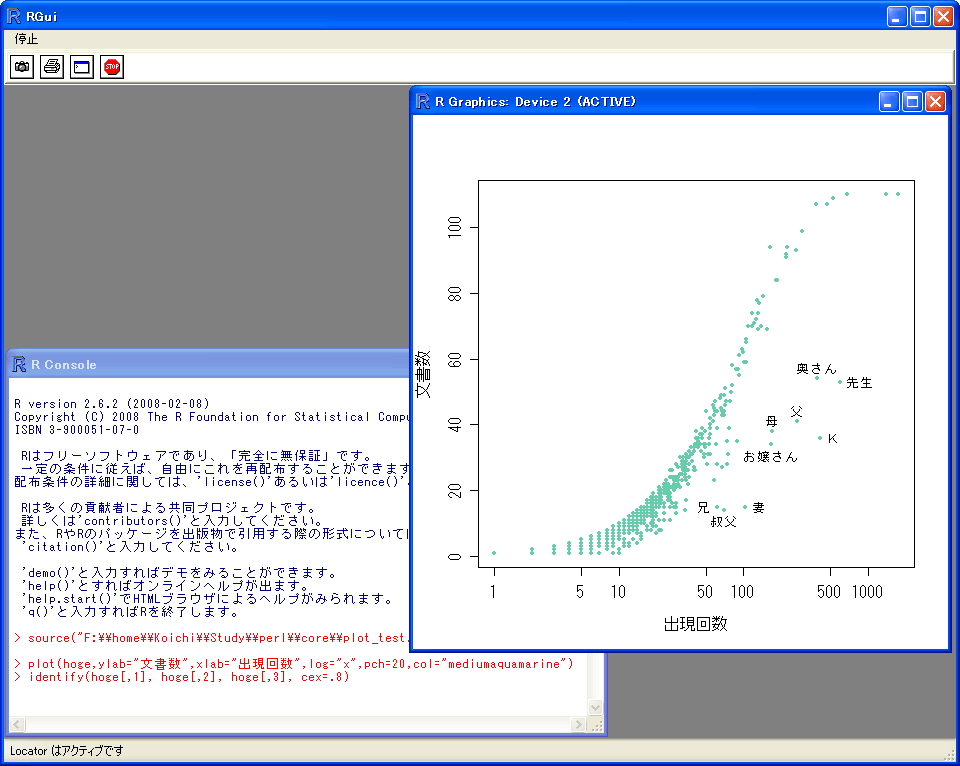
ここで4つ目の「R Source」形式を選択すると、各プロットを作成するためにRに送られたコマンドが、そのまま保存されます。保存したコマンドをRで実行すると、まったく同じプロットをR上で作成できます。また、コマンドの各種オプションを編集することで、プロットのカスタマイズを行えます。
 |
|
R上でカスタマイズ
|
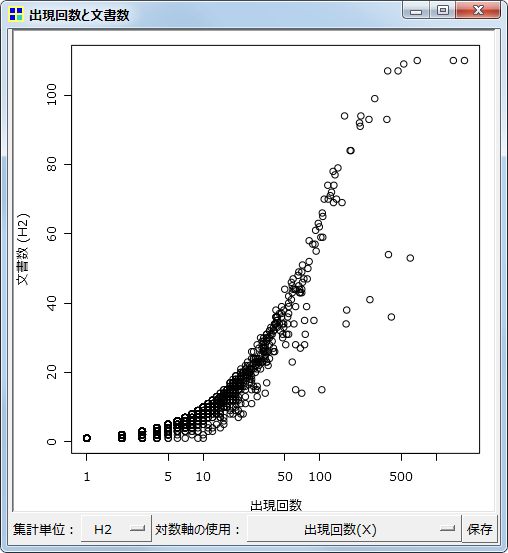
この例では、保存したファイルを実行して、さらにコマンドを2行追加することでカスタマイズしています。プロットの色を変えた上で、文書数が比較的少ないのに(すなわち比較的少ない数の章にしか出てきていないのに)、出現回数が相対的に多い語を「Identify」コマンドで特定しています。(このページの例はほぼすべて)漱石「こころ」をデータとして用いているのですが、主要な登場人物がここに出そろっています。
お使いいただくにあたって
これらの機能においては、KH Coder内部ではほとんど計算を行っていません。Rに解析コマンドを送り、Rが解析を行った結果を表示しています。プロット画面も自前の描画ではなく、Rが作成した画像ファイルを表示しているだけです。
このようないくぶん割り切った作りの機能なので、残念ながら、マウス操作でプロットの一部を選択してフォントを変えたりといったことはできません。こうした細かな調整や、より高度な解析、個別の目的に沿った解析については、上の例のようにR向けコマンドを編集・追加していただくか、あるいはお好みの統計ソフトウェアをお使い下さい。
|