 |
|
Version 3.Beta.07(2023/03/12-)での変更点
- 「文錦® ビジュアル プレゼンテーション for KH Coder」に対応 (3.Beta.07c)
- 細部の調整
- バグの修正
- 「関連語検索」画面の「共起ネット」ボタンをクリックするとエラーになる場合がある問題を修正(3.Beta.07f)
- プロジェクト作成後に外部変数を追加すると、文錦アドバンスドKWICがエラーになる問題を修正(3.Beta.07d)
- 多次元尺度構成法(MDS)のプロットを保存できない問題を修正
- 出現数が0のコードがあると、集計がエラーになる問題(最近のバージョンで混入)を修正
- コード名に半角ダブルクォート「"」が含まれるとエラーになる場合がある問題を修正
- 外部変数名に半角シングルクォート「'」が含まれるエラーになる場合がある問題を修正
Version 3.Beta.06(2022/11/26)での変更点
- 「文錦®バッチ ウィザード for KH Coder」に対応
- 細部の調整
- バグの修正
- 文番号の表示が不正確になる問題を修正 [Issue #537]
Version 3.Beta.05(2022/06/22)での変更点
- 対応分析と多次元尺度構成法でも上下左右の余白を設定できるようになった。バブルが切れてしまうのが嫌な場合などに。
掲示板でリクエストしていただいた、「余白」設定の機能を追加しました。 https://t.co/gYE1pwOE9d
— KH Coder (@khcoder) May 23, 2022
「掲示板のこの議論にもとづいて、プログラムをこう直した」と記録できるGitHubの機能、便利ですね。リンク先の「ko-ichi-h added a commit...」の部分です。1クリックでdiff(変更内容)も出ますし。 pic.twitter.com/mSY7Hf3Bt8 - KWICの抽出語入力欄に候補のポップアップ機能を備えた。
先ほどリリースした3.Beta.05bにて、候補のポップアップ機能をKWIC画面に追加しました。ポップアップしたら「↓」「↑」カーソル・キーで選択、「Enter」で検索できます。 pic.twitter.com/xLmwr9BPde
— KH Coder (@khcoder) August 4, 2022 - 共起ネットワークの線の太さを調節できるようになった
共起ネットワークの線の太さ、状況によっては細く見えることがあったので、調節できるようにしました。#次期バージョンの新機能 pic.twitter.com/qEG1fD1vvI
— KH Coder (@khcoder) June 21, 2022
Version 3.Beta.04(2022/04/24)での変更点
- 機能追加プラグイン「文錦® レポーティング for KH Coder」および「文錦® クレンジング for KH Coder」のバージョンアップに対応
- これまでのJaccard・Cosine・Euclidに加えて、SimpsonおよびDice係数を使用できるようになった。使用できるのは共起ネットワーク・多次元尺度法・階層的クラスター分析および関連語検索。Jaccard係数は、出現数に差がある語同士の共起を小さく見積もる傾向がある。たとえば、このスライドにおける語C・語Dとの共起を小さく見積もっている。小さく見積もる度合いをやや弱めたのがDiceで、完全になくしてしまったのがSimpson。
- インタフェース言語(メニュー・ボタン・ラベル等の言語)にフランス語を加えたほか、中国語の翻訳を修正した。フランス語についてはMaiKAJIWARA-HIRATAさんの、中国語についてはShun Wangさんの貢献によるものです。Contributorの方々に感謝申し上げます。なおフランス語・中国語ともに、今後さらに微修正が入るかもしれません。
- 細部の修正
- 多次元尺度構成法の仕様を変更した。これによって分析結果が変わる場合がある。
- 距離が0となる語のペアがあった場合、これまでは常に一方の語を分析から省いていた。その際には以下のような表示を出していた。
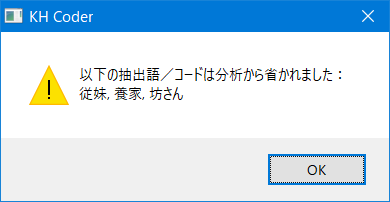
- しかし多次元尺度構成法のオプションで「Classical」「SMACOF」を選んでいれば、距離が0となる語のペアがあっても問題なく計算できるので、これら2つを選んでいるときは語を省かないようにした。
- 同オプションで「Kruskal」「Sammon」を選んでいる場合は、これまで同様に語を省く必要があるが、これまではペアのうちどちらか一方の任意の語を省いていた。3.Beta.04cからはペアの中で、出現数が少ない語を分析から省くことにした。
- 距離が0となる語のペアがあった場合、これまでは常に一方の語を分析から省いていた。その際には以下のような表示を出していた。
- 同じPC上で、複数のKH Coderを別フォルダに置いて使用する場合、同時に起動するとそれぞれのMySQLデータベースが混信して破損する危険がある。このような混信が起こっていないかチェックして、必要に応じて警告を出すようにした。
- Macで作成したテキストデータの濁点・半濁点(濁音・半濁音)が化ける問題に対応 [Issue #269, #284, #395]
- プロジェクト作成時に、以前に選択した形態素解析器(ChaSen or MeCab)を記憶するようにした
- プロットの表記を「rsd.」から「residuals」に修正した [Issue 452]
- 分析対象ファイルの名前に日本語文字が使われていた場合、Windowタイトルバーにおけるファイル名表示が文字化けする問題を修正。
- 日本語文字を含むフォルダにKH Coderを置いても、問題が起きにくいように修正した。ただし、いまだにC:\khcoder3のような英数字のみのフォルダ名の方が安全。
- 韓国語のパッチム(patchim)が分離する問題を修正した [Issue 481]
- 多次元尺度構成法の仕様を変更した。これによって分析結果が変わる場合がある。
Version 3.Beta.03(2021/09/07)での変更点
- トピックモデル(LDA)機能を追加した(3.Beta.03a)
- 「ツール」「文書」メニューに「トピックモデル」という項目を追加。
- スクリーンショットとごく大まかな使い方がTwitterのこちらスレッドに。
- Rのtopicmodelsパッケージに含まれるLDA関数を利用。ギブスサンプリングを指定して、乱数のシードを固定した以外はLDA関数のデフォルト設定。
- 乱数のシードを固定しているので、同じ設定で再度実行すれば同じ結果が得られる。
- トピック比率を集計してプロットする機能では、外部変数の値はカテゴリカルな値と想定。数値型の外部変数を使っていろいろなプロットを行ったり、相関を計算したり、回帰分析をするためには、現在のところ、データを出力して手動でグラフ作成・統計計算を行う必要あり。「トピック×単語確率」表と、「文書×トピック比率」表をまるごとCSV出力可。
- ※「LDAのこのパラメーターも設定したい」「このグラフを描く機能が足りない」などのご要望・ご感想など、よろしかったら掲示板やTwitterでお寄せください。
- 「前処理」「語の取捨選択」画面の「強制抽出」の欄に、「ネット利用」と「利用料金」のように、重複する部分のある言葉を入力した場合の挙動を修正した
- マニュアルには次のように記載していた:
この欄に複数の言葉を入力した場合,上の方に入力した言葉ほど優先順位が高いものとKH Coder は認識する。特に,重複する部分がある言葉を複数入力する場合には,優先順位を考えなければならない。たとえばこの欄に「ネット利用」と「利用料金」の両方を入力していて,分析対象ファイル内に「インターネット利用料金は年々低下している」という表現があった場合を考えてみよう。「ネット利用」の方を上に入力していた場合は,「インター/ネット利用/料金」という分割になり,「利用料金」という語は抽出されない。逆に「利用料金」の方が上に入力してあれば,「インターネット/利用料金」という分割になり,「ネット利用」は抽出されない。 - しかし実際には、上の方に入力した言葉ではなく、先に始まる言葉が優先的に取り出されていた。上の例では「ネット利用」の方が先に始まるので、どちらを上に入力しても「ネット利用」が取り出されていた。
- この挙動を修正し、マニュアルの記載通り、上の方に入力した言葉を優先して取り出すように修正した。「利用料金」を上に入力すれば、「ネット利用」ではなく「利用料金」が抽出されるようになった。
- 分析結果に影響がでる場合: ①「強制抽出」欄に上記「利用」のような重複のある複数の言葉を入力していて、なおかつ②分析対象テキスト中で上記「ネット利用料金」のような競合が発生していて、なおかつ③「強制抽出」欄で下の方に入力した言葉が分析対象テキスト中で先に始まっているという3つの条件が満たされる場合には、分析結果が変化する。以前は先に始まっていた言葉(下の方に入力した言葉)が強制抽出されたが、このバージョンからは上の方に入力した言葉が強制抽出される。
- 以前とまったく同じ分析結果を得るためには、必要に応じて前のバージョン(3.Beta.02fまたはそれ以前)をGithubからダウンロード・使用されたい。
- KH Coder公開当初よりこのような挙動となっていました。長期間にわたって、マニュアルに記載の説明とは異なる挙動となっていましたことを心よりお詫び申し上げます。
- マニュアルには次のように記載していた:
- 細部の修正
Version 3.Beta.02(2021/02/08)での変更点
- 「文錦アドバンストKWIC」に対応した
- 分析対象ファイルの扱いを変更し、ユーザー側の管理負担を軽減した [Twitter]
- 従来はExcelファイルを読み込むと、Excelファイルと同じ場所にテキスト形式に変換したファイル2つが出現していた。また、これらのファイルを削除するとプロジェクトを開けなくなっていた。これらの現象が起こらないようになった。
- 分析対象ファイルを削除すると従来はプロジェクトを開けなくなっていたが、問題なくプロジェクトを開けるようになった。
- KH Coderの内部フォルダに分析対処ファイルをコピーして、ここで必要なテキストファイルへの変換を行うことで、上記の改善を実現した。
- メニューから「前処理」「語の取捨選択」を選択し、「代名詞」にチェックを入れるだけで、代名詞を分析対象にできるようにした。KH Coderのデフォルトの設定では、代名詞は「どこにでも出現する一般的な言葉」として分析から除外している。ただし、代名詞を分析したい場合もあると考えられるので、簡単な操作で代名詞を分析対象に含められるようにした。従来は、品詞設定ファイルを編集する必要があった。 [Twitter]
- 色覚に特性のある方でも見分けやすいよう、対応分析のカラーリングを変更した [Twitter]
- 細部の調整
- MySQL 8に対応した
- Linux / Macで、スペースを含むパスに置いても動作するようになった(はず)
- バグ修正
- 分析対象ファイルが大きくなると、「エクスポート」「KH Coder形式(インポート可)」の処理に失敗する問題を修正した [Issue 222]
- Excel / CSV / TSVファイルの分析時に、分析対象とする列名に特殊文字(基本多言語面(BMP)の外にある文字)が含まれているとエラーになる問題を修正した [Issue 299]
- MDSのプロットをPDF形式で保存できないバグを修正した [Issue 296]
- 「インポート」「フォルダ内の複数テキスト」機能が正しく動作しない場合があるバグを修正した [Issue #261]
- ベイズ学習の分類ログファイル確認画面でコピーが正しく機能しないバグを修正した [Issue #271]
- Windows on ARMの環境では、32bit版のJAVAやRを使うことで、エラーを回避するようにした [Issue 295]
Version 3.Beta.01(2020/08/22)での変更点
- 設定画面に「基本形が同じ語は、品詞名が異なっていても同じ語と見なす」オプションを追加した。
- プロットをEMF形式で保存する際のファイル出力方式を変更した。Wordに貼り付けた後,PDFに変換した際,図が崩れにくくなった。
- 細部の調整
- データが日本語以外で、文字コード判別に失敗した場合、これまでは前処理を中断していたが、UTF-8と見なして処理を(やや強引に)続行するようにした。[Issue #177] [Issue #190]
- 抽出語リスト画面に、検索をリセットする「クリア」ボタンを追加した
- 対応分析において、外部変数の値・見出し・文書番号が200種類を超える場合、同時布置を行わないようにした。ラベルがあまりに多いと、適切な配置を見つけられずにRが固まる場合があるため。
- 使用環境によっては中国語データの前処理に失敗する問題について、考えられる対処法を盛り込んだ。64bitのWindowsで十分なRAMを積んでいれば、まず大丈夫ではないかと思うも、確認はまだ不十分。[Issue #224] [Issue #223] [Issue #196] [Issue #76]
- 一部のエラーメッセージを、より分かりやすい表現に改めた
- バグ修正
- 3.Alpha.17でのコーディング機能改良時に,出現数0のコードがあるとMySQLエラーでKH Coderが終了してしまうバグが混入していた。このバグを修正した。
- 外部変数の読み込み時に全角スペースを半角に変換するようにした。これがマニュアルに記載されている挙動だが、実際には変換が行われていなかったので、変換を行うよう修正した。この変換を行わないとコーディングがエラーになる場合がある。[Issue #174]
- 共起ネットワークの係数を表示する際、1以上の係数を表示できていなかった問題を修正した。[Issue #204]
- Windows環境で、別途インストール済みのRと競合を起こしてエラーになる場合がある問題を修正した。[Issue #225]
- MDSのプロットにおける凡例の表示がおかしくなるバグを修正した [Issue 237]
Version 3.Alpha.17での変更点
- 「プロジェクト」「インポート」「フォルダ内の複数テキスト」コマンドを新たに設けた。 従来はプラグインとして「テキストファイルの結合」コマンドがあったが,これに代わるコマンドである。今回新設のコマンドでは指定されたフォルダ内にあるテキストをすべて結合した上で,新規プロジェクト作成まで1ステップで行う。プラグインの「テキストファイルの結合」コマンドも,今のところは移行期間として残しているが,将来的には削除を予定している。
- コーディング
- コードを使った共起ネットワーク・対応分析・多次元尺度法等において,「出現数が0のコードは使用できない」というエラーが出ないようにした。単に出現数が0のコードを分析から省くようにした。
- 同じ名前のコードを定義した場合,コード名を変更して欲しい旨のエラーを表示するようにした。[Issue #128]
- プロット
- PDF / EMF / SVG形式でプロットを保存した際にも,フォントサイズ指定が反映されるようにした。これまではフォントサイズ指定が無視されていた。
- PNG形式での保存を高速化した。[Issue #115]
- Mac関連
- 起動時に一時ディレクトリを指定することで,一時ディレクトリの設定がおかしくても前処理が完了するように改善した。[Issue #110]
- 起動時にターミナル画面を自動的に最小化するようにした。[Issue #93]
- ファイルシステムが大文字小文字を区別する設定になっていても問題なく動作するよう改善した。
- 細部の調整
- Stanford POS TaggerやFreeLingとの通信を行うためのTCPポートを(coder.iniを編集することで)設定できるようになった。たまたまポートが別のプログラムに使われている/ブロックされていると,前処理がいつまでたっても終わらない場合がある。この場合は開いているポートを設定するとよい。[Issue #156]
- Windowsパッケージを利用せず,ご自身でMySQL5.7以降をインストールする場合に,MySQL5.7以降のデフォルト設定でKH Coderが動作するようにした。[Issue #85]
- Windowsパッケージを利用せず,ご自身でRをインストールする場合に,wordcloudパッケージのバージョンが2.6でもKH Coderが動作するようにした。[Issue #80]
- バグ修正
- 正常に動作していたのに,ある日,唐突に(設定ファイルが破損して)MySQLエラーが発生するようになる問題への対処を試みた。設定ファイル(coder.ini)が破損しにくいようにする工夫をいくつか行った。
- Excel / CSV / TSV形式のファイルから外部変数を読み込めない場合がある問題を修正した。外部変数が1つだけ(1列だけ)だと読み込みに失敗していた。 [Issue #75]
- アラビア語Windowsで共起ネットワーク作成時にエラーが発生する問題を修正した。 [Issue #78]
- MDSの結果をCSV形式で保存する際,エラーが発生する場合がある問題を修正した。 [Issue #164]
- コードの「類似度行列」画面の 「コピー」ボタンが機能しない問題を修正した。[Issue #112]
- 文書のクラスター分析のプロットを*.r形式で保存するときにエラーが発生する場合がある問題を修正した。
Version 3.Alpha.16での変更点
- 「文錦® 表記ゆれ&同義語エディター for KH Coder」に対応した
「文錦® 表記ゆれ&同義語エディター for KH Coder」が㈱SCREEN AS様より発売されました。 https://t.co/zzfCQ9T0lw 内蔵辞書を使って,「子ども」「お子様」「子供」などを一気に「子供」へと統一できます。 pic.twitter.com/ZEHFqZzMuE
— KH Coder (@khcoder) 2019年7月12日従来のKH Coderでは,こうした統一はコーディングルール内で手動で指定する形でした。コーディングという「大技」ないし「決戦兵器」を持ち出さずに,本プラグインで統一できれば便利なケースもあるでしょう。また「これとこれを統一しては」と自動提案してくれます。
— KH Coder (@khcoder) July 12, 2019ただし,自動提案をそのまま全部採用してしまうと,統一しすぎてしまう場合もあるかもしれません。まったく統一しない状態で一度分析してみたり,自動提案の内容を確認してから採用したりするのがお勧めです。
— KH Coder (@khcoder) July 12, 2019 - 大規模データ(文書数125万件超)を扱う場合でも,メモリ不足のエラーが発生しにくいように,ランダムサンプリングによってデータを縮小する機能を追加した。現在は抽出語のクラスター分析,共起ネットワーク,多次元尺度構成法,対応分析,自己組織化マップでこの機能を利用できる。
データが大きいと,Rによる可視化(共起ネットワーク等)がエラーになる場合がありました。Rは全データをメモリ上に読み出すためです。この問題を回避するため,Rに送るデータをランダムサンプリングによって縮小する機能を加えました。#次期バージョンの新機能 pic.twitter.com/0R63S6f8b5
— KH Coder (@khcoder) 2019年3月3日 - 「抽出語リスト」画面で検索を行う際,多くの検索結果があると画面表示に長い時間を要する(フリーズしたように見える)問題を修正した。
- Wordファイル(*.docx)を分析できるようになった。テキスト形式に自動変換する。
- 共起ネットワークの「調整」画面で余白を設定できるようになった。余白を指定することで,共起ネットワークの端が「はみ出す」というか「切れる」問題に手動で対処できる。
- 細部の調整
- 従来よりもIllustratorで開きやすいPDFを保存するようになった。「AdobePiStdフォントがない」と表示されてプロットが崩れる問題を修正。
- OracleのJAVAが有料化したことを受けて,Windows版パッケージにOpenJDKを同梱した。
- データ出力系のコマンドをメニューの一箇所に集めた。「プロジェクト」「エクスポート」メニュー。
- バグの修正
- コーディングルールにおいて抽出語の品詞指定を行った際に,MySQLエラーが発生する場合があるバグを修正した。
Version 3.Alpha.15での変更点
- SCREEN AS社のプラグイン「文錦®否定表現チェッカー」に対応した。
文章中で否定されている言葉を、「解る(否定)」といった形で、区別して抽出できるプラグインが㈱SCREEN ASより発売されています。「文錦™否定表現チェッカー for KH Coder」 https://t.co/uPaXQGxXqp 高価ですが、あると便利な時も?!
— KH Coder (@khcoder) 2019年1月29日まったく解らないよ → 「解る(否定)」
— KH Coder (@khcoder) 2019年1月29日
いまいち解りにくい → 「解る(否定)」
まぁ解らないこともないか → 「解る」
もし解らなければ尋ねるよ → 「解る」
…という感じで区別して抽出できます。文錦™シリーズは決して安価とは言えませんが、KH Coderがより便利に、より強力に。分析結果の中では,添付画像のような形で否定されている語が区別されるようです。「文錦™否定表現チェッカー for KH Coder」製品ページはこちらに→ https://t.co/tdMb5HE4lT pic.twitter.com/6hLaaEYvSo
— KH Coder (@khcoder) 2019年1月30日 - バブルプロットの凡例を調整する機能を追加した。
バブルプロットの凡例に、どの大きさの「見本」を表示するか、手動で調節する機能を準備中です。#次期バージョンの新機能 pic.twitter.com/RBoAyyFN5q
— KH Coder (@khcoder) 2019年1月20日 - Windows版パッケージにおいてMySQLとの通信方式をTCP/IPから名前付きパイプに変更した。従来はKH Coderを初めて起動する際にファイアーウォール警告が表示されていたが、この警告が出なくなったはず。
最新のKH Coder 3.Alpha.15(Windows版パッケージ) https://t.co/Mg4TuTdZTq ではMySQLと通信する際、従来のTCP/IPではなく、名前付きパイプを使うようにしました。これによって、ファイアーウォールの警告画面が出なくなりました。※誤字修正しました pic.twitter.com/0tzsUVtY5B
— KH Coder (@khcoder) 2018年12月23日 - 細部の調整
- 「分析対象ファイルのチェック」コマンドを「テキストのチェック」に改名した。名前のみの変更で、機能は変化していない。
- 「文書×抽出語」表をSPSSシンタックス形式で保存する場合、文字コードをBOM付きUTF-8として、新しいバージョンのSPSSでそのまま開けるようにした(3.Alpha.15d)。
- 「共起ネットワーク」コマンドで最初から作成するネットワークの種類を3つに減らした。これによって待ち時間がいくらか短くなった。従来同様に7ないし8種類を作成して見比べたい場合は、「調整」画面で「追加的なプロットを作成」にチェックする。
- テキストファイル中の空行は従来より無視してきたが、これまでは「文書表示」画面では空行として表示していた。この動作を変更し、空行を前処理時に自動的に削除するようにした。「文書表示」画面にも空行は表示されなくなる。従来は何千万行も空行を含むテキストファイルを分析使用とすると、前処理時にエラーが発生していたが、この修正によってエラーが生じなくなった。ただしExcelファイルの空行(空セル)については、「空のセルがあったもの」と認識する。このExcelファイルにおける空行の扱いについては従来と同様である。
- 「テキストのチェック」コマンドに機能を追加して,改行コードの不統一についても修正できるようにした。
- 外部変数の欠損値の扱いを修正した。対応分析や共起ネットワークにおいて、「missing」という値だけでなく、大文字小文字を区別せずに「Missing」「MISSING」なども欠損値として扱うようにした。
- 画面表示の中国語翻訳の書けていた部分を寄贈(pull request)していただいた。
- バグ修正
Version 3.Alpha.14での変更点
- CSV・Excelファイルの取り扱いを改善した
- Excel・CSVファイルを分析対象とした場合、従来はファイルを編集・更新しても自動的にはKH Coderの分析データに反映されなくて不便だった。この点を改善し、前処理時に変更内容を反映(再読み込み)可能とした。ファイルが更新されている場合は前処理実行時にダイアログが表示され、再読み込みを行うかどうか選択できる。
- タブ区切りファイル(*.tsv)の読み込みに対応した。
- MeCab関連の改善
- 処理を効率化し、前処理に必要な時間を短縮した
- MeCabに未知語の品詞推定をさせず、品詞名を「未知語」に固定した。これによって同じ「K」でも「名詞」と判定されたり「組織名」と判定されたりして、 複数種類の「K」が抽出される問題を軽減。
- MeCabを選択したプロジェクトではTermExtractによる「複合語検出」がエラーになる問題を修正した。
- 多次元尺度構成法(MDS)の改善
- 「クラスター化と色分け」を行なう際のクラスター数が従来は12までだったが、13以上も指定できるようにした。ただし20を超えると、色による識別はやや苦しくなる。
- バグの修正
- 共起ネットワークをEMF形式で保存した時に、色が失われてすべての語が白くなってしまう場合があるバグを修正した(3.a.14a)。
- KH Coderをインストールしたフォルダ名(フルパス)にスペースが含まれていると、FreeLingを使ったヨーロッパ言語データの前処理に失敗する問題を修正した(3.a.14a)。
- Windows 10のシステムロケールをUnicode(UTF-8)に設定すると、KH Coderが起動しなくなってしまうバグを修正した(3.a.14a)。
- KWICコンコーダンスにおいて追加条件の設定内容とデータによってはSQLエラーが発生する場合があるバグを修正した(3.a.14b)。
Version 3.Alpha.13での変更点
- SCREEN AS社のプラグイン「文錦レポーティング」に対応した。
- 文書のクラスター分析に改良を加えた(3.Alpha.13L)。
文書のデンドログラム(クラスター分析)を表示する際に、それぞれの文書のラベルとして任意の外部変数を使えるようになりました。画像の例では「ID」列をラベルとして使っています。#KHCoder3の新機能 さきほど3.Alpha.13jとしてリリースしました。 pic.twitter.com/mK1VIWInxI
— KH Coder (@khcoder) 2018年7月25日 - KH Coder 3の機能・仕様が固まってきたので、約1年ぶりに日本語マニュアル(khcoder_manual.pdf)の改訂を行なった(3.Alpha.13m)。
- バグの修正
- 「抽出語リスト」画面が開かない場合があるバグを修正した(3.Alpha.13a, 3.Alpha.13b, 3.Alpha.13f)。掲示板でのお知らせに感謝申し上げます。
- テキストと別言語の文字をコード名・変数に含めた場合、言語の組み合わせ次第ではエラーが発生する問題を修正した(3.Alpha.13g)。掲示板でのお知らせに感謝申し上げます。
- 日本語以外のテキストを分析するときに、日本語の句点「。」がテキストに含まれていると前処理がエラーになる問題を修正した(3.Alpha.13a)。
- 前処理の実行時にエラー・メッセージが出て止まってしまう場合があるバグを修正した(3.Alpha.13b)。
Version 3.Alpha.12での変更点
- 前処理の完了時や、外部変数の読み込み時にMySQLがデータをメモリからファイルに書き出すよう、「FLUSH TABLES」「FLUSH LOGS」を実行するようにした。MySQLが正常終了しなかった場合でも、データが破損しにくくなるようにと考えて、この変更を行なった。
- Windows版パッケージに同梱しているMySQLの設定を変更した。エンジンをInnoDBからMyISAMに変更した。上の変更と同様に、MySQLが正常終了しなかった場合でも、データが破損しにくくなるようにと考えてこの変更を行なった。また、この変更によって、サイズが大きいデータの前処理が比較的早く完了するようになっている。
Version 3.Alpha.11での変更点
- テキストデータの準備や、変数の整形を手軽に行なえるプラグイン(SCREEN AS社が販売)に対応した。
- 抽出語リスト機能を改善した。
「抽出語リスト」画面を作り直しています。#次期バージョンの新機能 共起ネットワークや対応分析に進む前に、基本的なものだって、頻出語リストだって、じっくり見れなくては!という趣旨です。(従来のExcel出力機能も残します) pic.twitter.com/h5bAvPZZwQ
— KH Coder (@khcoder) 2018年1月10日 - 同梱しているFreeLingのデフォルト設定を変更し、 連続する語を1語にまとめた、長い長い語が抽出されない様にした。設定ファイルを編集すれば、お好みの設定でご利用いただけます。
Version 3.Alpha.10での変更点
- これまでよりもサイズの大きなExcelファイルに対応した
- 新規プロジェクトの作成時にサイズが大きいExcelファイルを開くと、列の選択ができるようになるまでにKH Coderが固まったまま長い時間がかかったり、KH Coderが異常終了してしまう問題を修正した。
- 「新規プロジェクト」画面で「OK」をクリックした時の処理についても、データ全体をメモリ上に読み込まず、1行ずつ処理するように修正し、メモリ消費量を抑えた。
- 共起ネットワーク
- 配置をマウス操作で動かせる「インタラクティブHTML」形式で保存できるようになった
共起ネットワークについては、配置をマウスで操作できる「インタラクティブHTML」形式で保存できるようにしました。#次期バージョンの新機能 操作できる実物をこちらに置いています→ https://t.co/vWZfMBFG8X なかば遊びなんですけど、ちょっと楽しいような? pic.twitter.com/WtsL2wkfSP
— KH Coder (@khcoder) 2017年11月6日 - カラーリングを改善した
共起ネットワークの「サブグラフ」が12を超えると、従来はちょっと見分けにくいカラーリングになっていた点を改善しました。#次期バージョンの新機能 20までは見分けられるかと思います。 pic.twitter.com/h00hD6TmhJ
— KH Coder (@khcoder) 2017年11月6日 - 語をクリックすると、その語のKWICコンコーダンスを表示するようにした
共起ネットワーク上の語をクリックすると、KWICコンコーダンスを表示する機能を作成中です。 #次期バージョンの新機能 共起ネットワークだけを見るのではなく、もとの文にもあたりながら考えていただければ、というメッセージを込めています。 pic.twitter.com/eECBewSwU5
— KH Coder (@khcoder) 2017年11月16日
- 配置をマウス操作で動かせる「インタラクティブHTML」形式で保存できるようになった
- 対応分析に「原点付近を拡大」オプションを追加[スクリーンショット]
- カラーユニバーサルデザインに対応[スクリーンショット]
- 細部の調整
- 抽出語リストをExcel形式で書き出す際、従来は*.xls形式を用いていたが、*.xlsx形式を用いるように変更した(3a10i)。実際に問題が生じていたケースは希だろうが、XLS形式に起因する行数制限等が緩和された。
- 「複合語の検出」時に、複合語リストを*.xlsx形式で出力するようにした。従来のcsv形式だと、環境によっては文字コードの問題や、区切り文字の問題が生じるようだった。
- バグ修正
- 文書のクラスター分析の結果を保存しようとするとエラーになるバグを修正。※掲示板でお知らせいただき、大変ありがとうございます。このバグは3.Alpha.10で混入したものでした。
- Windows版で、複数言語の文字が混在していたりロシア語データを扱う際に、プロットの作成や保存に失敗する場合がある問題を修正した(3a10j)。
[2017 10/05]
Ver. 3.Alpha.9での変更点
- 共起ネットワークの機能を拡充
- 「外部変数・見出し・位置との相関をカラー表示」オプションを追加
データの前方で出現・共起しているほど青く、後方では赤くなるカラーリングです。#次期バージョンの新機能 物語の序盤では「先生」が、終盤には「K」「お嬢さん」「自分」が多いと一目で分かります。詳しく見ると、「父」は始め「病気」と共起しますが、物語が進むと「母」「兄」と共起するように。 pic.twitter.com/DMcJwcZSPK
— KH Coder (@khcoder) 2017年6月2日この機能 https://t.co/AeddMmXEOB 実は、KH Coder開発における久々の新機軸と考えています。これまでも、物語の上・中・下のうち上に特に多い(特徴的な)語・コードや、年配の回答者に特徴的な語・コードを探す機能はありました。対応分析や特徴語の検索など。→
— KH Coder (@khcoder) 2017年7月19日→しかし、データ中のある部分に特徴的な「共起」を探す機能はありませんでした。「年配の方の回答でのみ語Aと語Bが共起しがち」といった傾向を探す機能がなかったのです。使われ方や文脈が変われば、同じ語でも意味が変わります。こうした変化を、共起の変化から探ろうとする新機軸です。→
— KH Coder (@khcoder) 2017年7月19日 - 凡例を追加[スクリーンショット]
- 「外部変数・見出し・位置との相関をカラー表示」オプションを追加
- 日本語UTF-8の分析対象ファイルに、可能な範囲で対応した。ただし以下の制限がある。
- 「新規プロジェクト」画面で「ChaSen」ではなく「MeCab」を選択しなければならない。
- 基本多言語面(Basic Multilingual Plane)に入っていない文字はPerl/Tkの制限で画面上に表示できない。こうした文字は前処理時にすべて「?」に変換される。
- Windows版のRは、現在のロケールに含まれない文字を読み込めない。例えば日本語データ分析時には、ハングル文字や中国語漢字のようなCP932(Shift JIS)に含まれていない文字を読み込めない。こうした文字は、Rを用いた分析時にはHTMLの数値文字参照に変換される。
- 「分析対象ファイルのチェック」機能はChaSen向けに設計されており、UTF-8には対応していない。特に、自動修正を「実行」すると、EUC-JPで定義されていない文字がすべて削除されるので注意が必要。
- 細部の調整
- 抽出語リスト作成時に「頻出150語」を選択した場合、これまでは「感動詞」「未知語」を除外していた。一方で、対応分析・共起ネットワークなどの多変量解析のデフォルト設定には、これら2つの品詞が含まれていた。そこで品詞選択を統一するために、「頻出150語」にも「感動詞」「未知語」を含めるようにした。
- 数値を入力する欄に、全角の数字を入力してもエラーにならないようにした。
- BOM付きの分析対象ファイルに対応した。
- Windows版パッケージに添付のHanDicを最新版に更新した。
- バグの修正
- 「分析対象ファイルのチェック」を行なった後、見つかった問題点の詳細を「画面に表示」すると、KH Coderが異常終了する場合がある問題を修正。
- 前処理の直後にショートカット・キーが機能しなくなる問題を修正。
- 容量の大きいデータを分析しようとした時にMySQLエラー「lost connection to mysql server during query」が発生する場合がある問題を修正した。
[2017 08/03]
Ver. 3.Alpha.8での変更点
- ドイツ語データから従来よりも正確に言葉の基本形を取り出せるようになった。FreeLingの新しいバージョン(4.0)を利用することで実現。
- スロベニア語データの分析に対応した。同じくFreeLing 4.0を利用。
- Windows版パッケージに同梱の韓国語データ分析用の辞書「HanDic」を最新版に更新。
- プロットに凡例(カラー・バブル等)を追加
- 対応分析[スクリーンショット]
- 多次元尺度構成法(MDS)[スクリーンショット]
- コーディング結果のクロス集計[スクリーンショット]
- 細部の調整
- 共起ネットワーク作成時に、従来のJaccard係数だけでなく、Cosine係数やEuclid距離を選択できるようになった。
- UIの微修正により、操作性の改善を図った。Rによる多変量解析や描画に失敗した際、何度もエラーメッセージが表示されていたのを改善し、必要なエラーが1度だけ表示されるようにした。また分析対象ファイルとしてExcel・CSVファイルを登録したプロジェクトでは、対応分析の画面を開いたとき、デフォルトで「抽出語×外部変数」が選択されるようにした。
- 外部変数の値は最大2万字まで入力可能にした(従来は250文字まで)。ただし変数名は従来通り250文字まで。付加的な情報として長めの文章を入力しておき、「文書表示」画面で閲覧・確認したいといった場合むけの変更。
- OSの言語が日本語以外の場合は、メニューやボタンの表示を自動的に英語に変更するようにした。
- 対応分析の際に、変数の値が2種類しかない場合は、成分を1つだけ抽出し、その1つをプロットのX軸Y軸の両方に用いるようにした。
- バグ修正
[2017 01/15]
Ver. 3.Alpha.7での変更点
- H1からH5タグで括った見出しの扱いを変更した。
- こうした見出しも1つの「文」と見なして数えるのが従来の仕様であった。しかしExcel形式のファイルを読み込んだときや、多数のテキストファイルを自動的に1つにまとめた時には、データを区切るために、自動的に見出し文が挿入される。こうした自動挿入された単なる区切りは、「文」として数えないようにした。
- 詳細は同梱マニュアルのA.2.1節、「それぞれの単位でのコーディングや検索」
の項に記載。 - この問題については掲示板でご示唆をいただきました。ありがとうございます。
[2016 03/28]
Ver. 3.Alpha.6での変更点
- ロシア語およびカタロニア語のデータ分析に対応した。語の抽出にはFreeLingを利用。
- フランス語・イタリア語・ポルトガル語・スペイン語への対応が改善した。従来は単純なルールで語尾を切り落とすことしかできなかったが、FreeLingを使うことで、より正確に基本形に直して抽出できるようになった。
[2016 01/20]
Ver. 3.Alpha.5での変更点
- 文字コード関連の細かなバグをいくつか修正した。
[2016 01/14]
Ver. 3.Alpha.4での変更点
- 共起ネットワークコマンドに「係数を表示」オプションを追加した[スクリーンショット](3.Alpha.4a)。
- 共起関係の強さ(Jaccard係数)をネットワークに表示する
- 線が密集すると読み取りにくくなるが、「最小スパニング・ツリーだけを描画」オプションと併用すると読み取りやすくなる
- 共起ネットワークをGraphML形式およびPajek形式で保存できるようにした[スクリーンショット1][スクリーンショット2](3.Alpha.4b)。
- たとえばCytoscapeでGraphML形式のファイルを開けば、マウス操作でネットワーク(グラフ)の見栄えを変更できる。
- Pajekについては『Pajekを活用した社会ネットワーク分析』という書籍が詳しい。
- 対応分析と多次元尺度構成法の結果をCSV形式で保存できるようにした[スクリーンショット1][スクリーンショット2](3.Alpha.4c)。ExcelのほかJMPやSPSSなど、他のソフトウェアでプロットを作り直したい時には便利だろう。
- 画面表示(メニュー・ボタン・ラベル等)の言語として中国語と韓国語を追加した。
- ※ただし、KH Coderに詳しくない方に翻訳をお願いしたので、おそらく訳が完全ではない部分もあると思います。お気づきの点がありましたら、より良い訳し方とあわせてお知らせいただけると大変ありがたく存じます。
- MeCab向け韓国語辞書「HanDic」の新しいバージョンがリリースされていたので、同梱のHanDicを新しいバージョンに差し替えた。
[2015 11/29]
Ver. 3.Alpha.3での変更点
- 韓国語データの分析に対応した。
- 韓国語データから語を取り出すために、MeCab向けの韓国語辞書「HanDic」を利用(Windows版パッケージには同梱)。
- なおKH Coderで利用するために「HanDic」に付属のdicrcファイルに次の記述を追加している。
; ChaSen
node-format-chasen = %f[6]\t%M\t%f[5]\t%F-[0,1,2]\t%f[3]\t%f[4]\n
unk-format-chasen = %f[6]\t%M\t%f[6]\t%F-[0,1,2]\t\t\n
eos-format-chasen = EOS\n
- MDS(多次元尺度構成法)コマンドを拡充した[スクリーンショット](3.Alpha.3d)。
- SMACOFアルゴリズムを選択できるようにした。
- 「ランダムスタートを繰り返してより良い解を探す」オプションを追加した。
- バグの修正
- 「語の取捨選択」画面の「ファイルから読み込み」機能が正常に機能しない場合がある問題を修正した。
- コンソール出力が一部文字化けしていた問題を修正した。
- 韓国語版Windows上では起動しない問題を修正した(3.Alpha.3a)。
- ユーザーが自身でRと最新版のigraphパッケージをインストールしていると、共起ネットワーク作成に失敗する場合がある問題を修正した(3.Alpha.3b)。
- 韓国語データの分析時に、「外部変数と見出し」画面で「特徴語」「一覧」をクリックするとエラーになる問題を修正した(3.Alpha.3b)。
- 「分析対象ファイルのチェック」実行や、その後の「自動修正」に失敗する場合がある問題を終始した(3.Alpha.3d)。
[2015 11/01]
Ver. 3.Alpha.2での変更点
- 細部の調整
- 外部変数の値の表示順が従来はVer. 2と異なっていたので、Ver.2と同じ順番で表示されるようにした。これによってコーディング結果のクロス集計や外部変数を用いた対応分析の結果が、並び順のような見た目も含めて、Ver. 2の結果と同一になった。
- 抽出語とコードを使った各種の集計結果がVer. 2と同じになることを確認した。
- Ver. 2.00aおよび2.00bでの修正点をこちらにも取り入れた。
- バグの修正
- 前処理実行時にMySQLエラーが表示され、前処理が完了できない場合がある問題を修正した。
- 中国語データのKWICコンコーダンスで、単語間に余分なスペースが入るバグを修正した。
Ver. 3.Alpha.1での変更点
- 中国語データの分析に対応
- 中国語データは簡体字・UTF-8で準備する必要がある。Stanford Word SegmenterおよびStanford POS Taggerを用いて中国語データから語を抽出。
- 中国語データのKWICコンコーダンスで、単語間に余分なスペースが入っていた問題を修正した(3.alpha.2)。
- アクセント付きアルファベットを保存・表示できるようになった。
- フランス語・ドイツ語・スペイン語などをあつかう際、これまではアルファベットについているアクセント記号を削除していた。このアクセント記号を保存・表示できるようになった。
- Ver. 3で仕様が変更になった点
- 「文書×抽出語」表における文書長(文字数・length_c)は、ver. 2では半角文字を0.5文字、全角文字を1文字とカウントしていたが、Ver. 3では半角全角にかかわらず1文字と数えるようになった。
- 全角記号のみからなる語がver. 2では「未知語」品詞を与えられていたが、ver. 3では「その他」品詞を与えるようになった。
- ver. 2.xでは外部変数の大文字と小文字が区別されたが、3.xでは大文字と小文字を区別せず、同じものと見なしている。
- 「KWICコンコーダンス」および「関連語検索」機能で表示の順番を決めるときに、たとえば語の出現回数が同じ回数であるといったように、同順・同値になった部分があると、その部分の表示順がver. 2とは一部異なっている。
[2015 08/15]
[ KH Coder ]
KH Coderの本(サポートページへ)

リスク社会を生きる若者たち ※第9章にKH Coder開発者によるアンケート自由記述の分析例

文章を科学する ※『赤毛のアン』英語原文の分析例と、言語学的な分析のための手順など

コーパスとテキストマイニング ※KH Coderによるアンケート自由記述の分析について解説あり

Rのパッケージおよびツールの作成と応用 ※KH Coderによる分析を自動化したり、新たな機能を追加する方法の解説あり

言語研究のための統計入門(勝手サポートページへ) ※対応分析・クラスター分析等についての解説・利用例・KH Coderによる練習問題